
HOWTO: Search and Destroy “Unlabeled” mail in Google Gmail
Tags: email, Gmail, googleI have over 14 years of email stored in Google Gmail now, all sorted, organized and tagged. It’s a huge archive going back through several jobs, plenty of experiences personal and professional. Some day it might make a good bit of data mining for an autobiography, but I digress..
One thing about Google Gmail has been bugging me for years! Google “folds” mail away in your Inbox, out of view, hidden, but not in any folder (what Google calls “Labels”, but they’re really individual IMAP folders).
There doesn’t seem to be any sort of reason for this, no algorithm and no obvious method to why they decide to take email out of your Inbox and hide it away from you. A bug? A feature? Who knows, but it’s annoying.
Here’s an example of what this looks like:

Notice that my search for “pinbot@pinterest.com” (Pinterest‘s mail robot) returns several hits, but only one of which is in my “Inbox”. Those others appear nowhere. They’re not in any folder anywhere in my entire IMAP or Gmail heirarchy.
They’re completely hidden, invisible, and only show up when you do a specific search for those terms. In other words, you can’t clean that junk out, delete it, unless you search for it first. Chicken-and-Egg problem, because you can’t search for what you don’t know exists.
There have been hundreds and hundreds of posts trying to come up with solutions to this problem, including using the “-label:” syntax to exclude labels from the search, leaving only “unlabeled” email.
That works great, if you have a handful of labels, maybe a dozen or two, but I have hundreds of IMAP folders (erm, “labels”), and they’re nested pretty deep in some cases. Trying to append all of my labels into one big long search string, does not work, because of a string limit in the search field. Fail.
So then I tried the somewhat magical “-label:*” search, but it returns mail with labels too, for some randomly odd reason. Another fail.
Then I tripped on someone who has a more elegant solution to the problem, rolled up into a Greasemonkey extension. Enter “gmailUnlabelled“!
Once you install the extension, you’ll find a new “Unlabelled” link on the left side, in your labels group. Clicking that will reveal email with no labels, the “hidden” email that Gmail ferrets away from you, away from your searches, away from your folders.
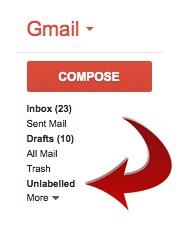
Find it, label it, or as in my case, kill it off. I have 10,543 emails in my “All Mail” folder, and I’m sure a few hundred to a few thousand are going to fall into the Unlabeled category.
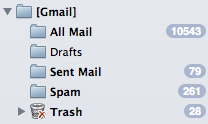
Now I can begin the process of pruning that out and cleaning out my mail even further. I hope this helps others who may be facing the same problems.
SOLVED: Calendar Printing Assistant for Office 2010
Tags: CPA, google, GUI, microsoft, Printing Assistant, VMware, Windows 7 I installed the “Calendar Printing Assistant” for Office 2007 in a VM, and was very impressed with the output. Slick and lots of choices.
I installed the “Calendar Printing Assistant” for Office 2007 in a VM, and was very impressed with the output. Slick and lots of choices.
I recently upgraded to Office 2010, and have been tinkering with the conversion of my Office 2007 daily usage in a VM to the Office 2010 usage in a VM, but missed the power and flexibility of the Calendar Printing Assistant.
If you Google the tool, you come to this page on Microsoft’s site, which refers to ‘version 4’ of the CPA. Unfortunately, this only works with Office 2007, not Office 2010.
In fact, if you search around some more, you even find posts from Microsoft themselves, saying that it isn’t updated to handle Office 2010 yet.
Being one to never give up, I kept digging, and digging, and digging… and after many searches through Microsoft’s site directly, I found it! The Calendar Printing Assistant for Office 2010 (and Office 2007), “updated” to version 2.0.
Microsoft Calendar Printing Assistant for Microsoft Office 2007 (12.0.6520.3001) MSO (12.0.6520.5000)
I just verified that it does indeed install and work on Office 2010, without any issues at all… other than some GUI artifacts (probably due to some funky VMware video drivers for Windows 7, more than CPA itself).
Enjoy!
Validating Blog Pingback Sites with Perl
Tags: google, Perl, serversOver the last few months I’ve been wondering what the slow response time has been when I am posting new entries to my blog. Granted, the hits to my blog have more than tripled in the last 2-3 months, but my servers can handle that load. The problem was clearly elsewhere.
Some more digging and I realized that the list of 116 ping sites I have in my blog’s “Update Services” list contains quite a few pingback sites that are no longer valid.
For those new to this, a “Pingback” is a specifically-designed XML-RPC request sent from one website (A, usually a blog site) to another site (B) in response to a new entry being posted on the site.
In order for pings (not to be confused with ICMP pings) to work properly, it requires a physical link in the form of a URL to validate. When (B) receives the notification signal from (A), it automatically goes back to (A) checking for the existence of a live incoming link to (B). If that link exists, the Pingback is recorded successfully.
This “validation” process makes it much less prone to spam attacks than something like Trackbacks. If you’re interested in reading more about how spammers are using Pingbacks and Trackbacks to their advantage, I suggest reading Blog trackback Spam analysis on the “From Information to Intelligence” blog site.
But I needed a way to test all of those ping sites and exclude the ones that are dead, down or throwing invalid HTTP responses… so I turned to Perl, of course!
My list of ping sites is a sorted, uniq’d plain-text list that has one ping site per-line. The list looks something like this:
http://api.moreover.com/ping http://bitacoras.net/ping http://blog.goo.ne.jp/XMLRPC http://blogoole.com/ping http://blogsearch.google.com/ping/RPC2 http://godesigngroup.com http://godesigngroup.com/blog/feed http://imblogs.net/ping http://ping.bitacoras.com http://ping.bloggers.jp/rpc http://ping.blo.gs http://pinger.blogflux.com/rpc http://pinger.onejavastreet.com/ http://ping.myblog.jp http://pingoat.com http://pingomatic.com http://rcs.datashed.net/RPC2 http://rpc.blogbuzzmachine.com/RPC2 http://rpc.blogrolling.com/pinger http://rpc.pingomatic.com http://rpc.weblogs.com/RPC2 http://rpc.wpkeys.com ...
I pass that list into my perl script and using one of my favorite modules (File::Slurp), I read that file and process each line with the following script:
use strict;
use URI;
use File::Slurp;
use HTTP::Request;
use LWP::UserAgent;
my @ping_sites = read_file("pings");
my @valid_ping_sites = ();
for my $untested (@ping_sites) {
my $url = URI->new($untested);
my $ua = LWP::UserAgent->new;
$ua->agent('blog.gnu Ping Spider, v0.1 [rss]');
$ua->timeout(10);
my $req = HTTP::Request->new(HEAD=>"$untested");
my $resp = $ua->request($req);
my $status_line = $resp->status_line;
(my $status) = $status_line =~ m/(\d+)/;
if ($status == '200') {
push @valid_ping_sites, "$url\n";
} else {
print "[$status] for $url..\n";
}
}
my $output = write_file("pings.valid", @valid_ping_sites);
The output is written to a file called “pings.valid“, which contains all of the sites which return a valid 200 HTTP response. The remainder are sent to STDOUT, resulting in the following output:
$ perl ./pings.pl [403] for http://1470.net/api/ping.. [403] for http://api.feedster.com/ping.. [404] for http://bblog.com/ping.php.. [500] for http://blogbot.dk/io/xml-rpc.php.. [403] for http://blogmatcher.com/u.php.. [500] for http://blogsnow.com/ping.. [404] for http://fgiasson.com/pings/ping.php.. [404] for http://pingoat.com/goat/RPC2.. [500] for http://ping.syndic8.com/xmlrpc.php.. [500] for http://ping.weblogalot.com/rpc.php.. [403] for http://popdex.com/addsite.php.. [404] for http://www.blogdigger.com/RPC2.. [500] for http://www.blogsnow.com/ping.. [500] for http://www.blogstreet.com/xrbin/xmlrpc.cgi.. [404] for http://www.catapings.com/ping.php.. [500] for http://www.focuslook.com/ping.php.. [500] for http://www.holycowdude.com/rpc/ping.. [403] for http://www.popdex.com/addsite.php.. [500] for http://xmlrpc.blogg.de.. ...
Those failed entries are then excluded from my list, which I import back into WordPress under “Settings → Writing → Update Services”.
The complete, VALID list of ping sites as of the date of this blog posting are the following 49 sites (marking 58% of the list I started with as invalid):
http://1470.net/api/ping
http://api.feedster.com/ping
http://api.moreover.com/ping
http://bblog.com/ping.php
http://bitacoras.net/ping
http://blogbot.dk/io/xml-rpc.php
http://blog.goo.ne.jp/XMLRPC
http://blogmatcher.com/u.php
http://blogoole.com/ping
http://blogsearch.google.com/ping/RPC2
http://blogsnow.com/ping
http://fgiasson.com/pings/ping.php
http://godesigngroup.com
http://godesigngroup.com/blog/feed
http://imblogs.net/ping
http://ping.bitacoras.com
http://ping.bloggers.jp/rpc
http://ping.blo.gs
http://pinger.blogflux.com/rpc
http://pinger.onejavastreet.com/
http://ping.myblog.jp
http://pingoat.com
http://pingoat.com/goat/RPC2
http://pingomatic.com
http://ping.syndic8.com/xmlrpc.php
http://ping.weblogalot.com/rpc.php
http://popdex.com/addsite.php
http://rcs.datashed.net/RPC2
http://rpc.blogbuzzmachine.com/RPC2
http://rpc.blogrolling.com/pinger
http://rpc.pingomatic.com
http://rpc.weblogs.com/RPC2
http://rpc.wpkeys.com
http://www.a2b.cc/setloc/bp.a2b
http://www.blogdigger.com/RPC2
http://www.blogsdominicanos.com/ping/
http://www.blogsnow.com/ping
http://www.blogstreet.com/xrbin/xmlrpc.cgi
http://www.catapings.com/ping.php
http://www.feedsky.com/api/RPC2
http://www.focuslook.com/ping.php
http://www.godesigngroup.com
http://www.holycowdude.com/rpc/ping
http://www.imblogs.net/ping
http://www.pingmyblog.com/
http://www.popdex.com/addsite.php
http://www.wasalive.com/ping/
http://www.xianguo.com/xmlrpc/ping.php
http://xmlrpc.blogg.deFeel free to use this list in your own blog or pingback list.
If you have sites that aren’t on this list, add them to the comments and I’ll keep this list updated with any new ones that arrive.
Amateur spammer trying to sell me SEO services
Tags: googleThis one almost looked legitimate, and I actually replied to his email. What made me sure this was spam was that my reply back to him was met with an exact duplicate of his original email, sent back to me.
The original email started out like this:
I was looking at websites under the keyword Groton hosting and came across your site http://resume.gnu-designs.com . I see that you’re ranked 71 on page 8 in google.
I’m not sure if you’re aware of why you’re ranked this low but more importantly how easy it is to start getting higher listings in search engine results.
All you need to do is some simple “link publicity” for your website and you could quickly hit the front page and work your way up to #1-#3.
… over the last 5 years we took the website [REMOVED] from only 50-100 clicks per day from Search Engines up to 49,000! clicks per day! (generating $23M in sales last year!)
How?
Well, by having quality articles written about this website which were then published by many blogs, web 2.0 websites, and many other well respected websites on the internet… amongst slowly adding hundreds and now tens of thousands of highly optimized content pages to his site.
The email then went on to show some (likely falsified) numbers about the growth of the site he referenced above. I looked up the Alexa ranking and could not verify his claims.
His email continued with…
We were paid over six figures for optimizing those two sites alone and the clients are making a huge
ROI from their investment!Your keyword: Groton hosting
Is NOT competitive and I now have a large team to allow me to serve smaller businesses such as
yours for pennies on the dollar – for a fraction of what those clients paid – you too can enjoy the
fruit’s of Top 10 rankings in google for your target keywords.
I replied back in a very nice way, showing that my RESUME page is not linked to from anywhere external that I know of (well, I just linked to it above in this post) and that the text version of my resume is ranking at PR2. The main HTML index page is a PR3, without any marketing or promotion whatsoever.
I also included some of my higher-ranking websites, which are currently PR5, PR6 and PR7 with over 18k unique visitors per-day on the highest ranked site I host. These are all in the top 5 (not just the top 10) SERPS (Search Result Pages) in Google for VERY broad search terms.
Here are a few examples using some VERY broad keywords:
We’re currently ranking at #2 for html reader on one website.
Slightly narrowed, but still very broad search, and we come in at #1 for palm html reader for the same site.
Here are some more across a bunch of random sites I host:
- #1 for wxchar to hex
- #1 for truecrypt ext3
- #1 for vmw_have_epoll
- #1 and #2: vmware infrared
- #4 for ebook viewer
- #4 for ip range by country
- #4 for proxy page
- #8 for hotsync
…and so on. I haven’t done a lick of marketing to promote any of the sites above, and they’re already pulling in a lot of traffic and are getting in the top 10 in Google’s SERPS.
I asked “SEO Charles” to get back to me, if he thought he could get my PR7 sites up to PR8, or double my incoming traffic without falsifying backlinks or using any other malicious means. Instead, he emailed me another copy of the same exact email he sent the first time, spamming me.
So I just dealt with it as follows..
From his mail headers, I abstracted:
Return-Path: <bounces+255129.16977265.204142@icpbounce.com> Received: from smtp7.icpbounce.com (smtp7.icpbounce.com [216.27.93.119])
Then a little more digging revealed this detail about that IP range from Project Honeypot:
I then sent him an email, letting him know that his entire netblock was being blocked for being an ignorant, amateur “SEO Expert”, as well as a known public spammer.
iptables to the rescue! (broken hostnames here to avoid giving him any PR):
$ host 216.27.93.119 119.93.27.216.in-addr.arpa domain name pointer smtp7.ic pbou nce.com. $ sudo iptables -A INPUT -s 216.27.93.0/24 -p tcp -m tcp -j DROP $ host ge tran ked1.com getr anked1.com has address 74.53.25.226 getrank ed1.com mail is handled by 0 ge tranked1.com. $ sudo iptables -A INPUT -s 74.53.25.0/24 -p tcp -m tcp -j DROP
Problem solved.
Oh, and if you want “Groton hosting” (or hosting in Groton, CT. or anywhere else in the world for that matter), visit my ACTUAL hosting page, not my resume page.
Novell Evolution Tip of the Day: Subscribing to Google Calendars
Tags: Calendar, Evolution, google, linuxAs I continue to shave and optimize my hybrid working environment to gain more productivity out of the limited hours I have in every day, I’ve been working on consolidating my calendaring needs across the three platforms I currently use (soon to be 4):
- Linux Development environment (I do everything on Linux)
- Windows Financial environment (I use this for Microsoft Money, some Office 2007 work and several Palm conduits and plugins that don’t have Linux equivalents)
- Web
- Mac OS X (not yet introduced into my workflow)
I have a lot of calendar items that need to be in various places so I can get to them when I’m working on that platform. This means when I’m on Linux, I need to see my calendar in Evolution and J-Pilot.
When I’m in Windows, I need to see the same calendar in Microsoft Outlook.
When I’m in a browser or not on my native Linux or Windows machines, I need to be able to see my calendar in Google Calendar.
All three platforms must reflect the same EXACT data, without being out of step with any other. So far, this is working very well, using my Palm Treo680 as the middle-man delivery mechanism.
Recently it came to my attention that I need to have clients see where my free/busy time is, and start booking their own slots of my time into the free spots that I haven’t personally blocked out yet.
To do this, I’ve had to leverage and expose my Google Calendar to the public.
On Windows, I’m using a tool called “CompanionLink for Google Calendar” to get my calendar data from Treo → Outlook → Google Calendar. It’s non-free, but it had a decent trial period and its usefulness won me over, so I registered it.
But there was no obvious way to get Evolution to read back those calendars, so I could see when external people (i.e. friends, clients) were adding things to my calendar to book my time for them.
Enter “evolution-webcal”, a seldom-discussed binary that lives in /usr/lib/evolution-webcal/ on most GNU systems (/opt/gnome/lib/evolution-webcal/ on SuSE)!
Basically all you have to do to get Evolution to read in your Google Calendar calendar files is the following (all on one line):
$ /usr/lib/evolution-webcal/evolution-webcal \ http://www.google.com/calendar/ical/p%23weather%40group.v.calendar.google.com/public/basic.ics
The way you get the .ics calendar URL you see above, is by:
- Log into your Google Calendar account
- Click the little “V” chevron to the right of your target calendar in the “My Calendars” block on the left sidebar
- Select “Calendar Settings” from the popup menu
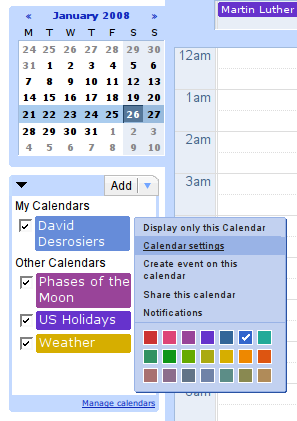
- Towards the bottom of the “Calendar Details” tab on the right side, you’ll see two sections: Calendar Address and Private Address. Click the [ICAL] item on either of these (choose wisely)
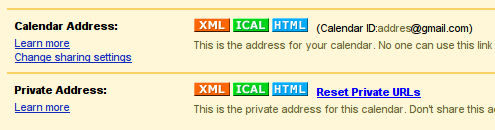
- Cut and paste the URL provided in the popup window into your evolution-webcal command above.
That’s it. Now Evolution will have your new Google Calendars listed under the “On the Web” category in the Calendar’s view.
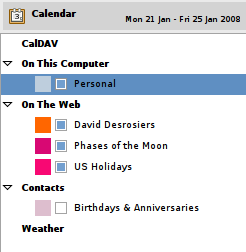
Now I can see the same thing in Evolution as I see in Outlook as I see in Google Calendar, without any discrepancies. Whew!
If Mozilla Thunderbird is your thing, there’s an extension to Thunderbird called “Provider for Google Calendar” that allows you to read/write to your Google Calendars from within Thunderbird.
It’s a start. Now where did I put those extra 32 hours I need in every day again?
Solution to prc-tools on AMD64 and other 64-bit machines
Tags: google, linux, servers, VMwareIf you’re like me, moving to the latest 64-bit hardware has made an ENORMOUS difference in my productivity. I’ve moved all of my personal machines and servers to AMD64/4600+ machines with a minimum of 4gb of RAM.
The problem is that not everything moves over so seamlessly; case in point: prc-tools. The problem with prc-tools not functioning on AMD64 has nothing to do with John Marshall, the maintainer of prc-tools… John is a great person, once you get used to how he works and how he expects bug reports and submissions <ducking from johnm’s swing>
I use prc-tools in several-dozen hourly cron jobs to build Palm software for projects like Plucker and several others, and I wanted to decommission the existing AMD32 machine that was doing those builds up to this point to migrate everything to the faster, less power-hungry AMD64 machines.
I didn’t really want to have to move everything to the new AMD64 machines EXCEPT this one AMD32 machine powered up @400W 24×7 just to build Palm software. That would cost me too much money each month in power costs for a server which isn’t really being used for anything other than cranking out hourly builds of Palm software.
prc-tools is a series of patches to the mainline gcc compiler that we’re all used to using on Linux and other POSIX systems like BSD and Solaris. The problem is that the prc-tools patches are mated to gcc-2.95, which was released back in July 31 of 1999. 64-bitness didn’t even exist back in 1999, 8 years ago.
I’m also not the only one with this problem.
I started patching up gcc’s configuration files to detect 64-bit procs a bit better, but it dead-ended quite early. The autoconfiscation process doesn’t even detect the architecture via config.guess. Dropping in a more-recent config.guess and rewrapping configure.ac helped a little bit, but it died further on in the process. Iterative fixes got it quite far, but eventually I had to dive into gcc itself to patch it, and that’s an area I leave to more-seasoned experts than myself.
Read the rest of this entry »
Mailing List Hijacking
Tags: google, serversI briefly corresponded with a user who was asking for access to CVS for pilot-link, to try to solve a problem he was having with photos on his Palm.
I mentioned that CVS was not public, and he responded that he googled around and found a message from me on a mailing list I run, that helped him out.
“Wait, how did google spider a list that I know I restrict them from being able to index…”
So I started googling, and found this little site. It is a site in .ph (the Phillapines).
The problem with this, isn’t really that they provide an offsite archive of lists, but that they remove all email obfuscation from the posts. This means anyone posting to my lists, under the knowledge that their email address will be protected (by my site configuration and Mailman itself), will no longer have that address protected when it gets indexed by this site in .ph.
I also noticed a few moderated lists there, which I know have member-only viewable archives. This means you can’t google around and find posts made in those archives… except that google spiders THIS site, and picks them up, including the user’s email addresses.
I sent the webmaster a VERY harsh email about the situation, giving him a deadline of 5 days to remove any and all references to our lists from his/their servers. I also blocked their entire netblock on port 25 and 80, so he can’t even fetch the mbox version of the archives, and I unsubscribed the user “lurker” from all of the lists I run here.
We’ll see what happens. Probably nothing, but at least I can stop rogue users from subscribing to the list, purely for the purpose of putting list archives somewhere else on the Interweb.
Diary of a Diary
Tags: googlelilo, apparently you don’t quite understand how the diary rating system works. I have personally rated approximately 4 diary entries, total. What you’ve seen in the report for myself, rasmus and others does not mean we sit here all day and rate people’s diaries. Please go re-read the code again. We have lives. Please consider worrying more about your own, than making assertions about ours.
These petty little attacks you make on those who don’t agree with your “philosophies” don’t bode well for your perceived status in the “community” you claim to support. Once again, you show how far you can read into a situation that has absolutely nothing at all to do with you. Nobody has a “personal agenda” that the rating system here on Advogato is being used to exploit.
Also, that little stunt with the FSF has generated some “offline” interest. Call have been made, and there are quite a few people (including at least two well-funded companies) who are now witholding their donations to the FSF, until they can guarantee that not one single cent of their FSF-destined funds makes its way to PDPC or the lilo-fund.
Other Advogato Abuse
The eBay laptop fraud saga continues. I was contacted on August 1st by an officer in the New York Police department regarding Brian Silverman, aka “electro_depot” from my diary entry about it here. Since the beginning, my diary was the only one that would show up in a google search on electro_depot. Over 120 people have contacted me regarding that diary entry, including one person who created his own website to combat the fraud. He also directly mentions why he started the site due to finding my diary entry here. There’s also a Yahoo group on it as well.
The end result is that I joined the Yahoo group, and was banned because I explained the details of the fraud, and because I received my laptop, after a very “firm” phone call with Brian Silverman. The replies I made to other people on that group were also deleted, preserving only the opinion of the original poster, which, I might add, was entirely incorrect and misleading to the victims of this fraud.
So now we have a spammer on Advogato, adam12497, who has used advogato like a classified advertisement in the newspaper, trying to draw people’s attention to his Yahoo group on the matter, abusing what Advogato stands for. I’ve emailed raph twice about it. I stand with raph on the issue of deleting persons here, but I think this one makes a very strong exception to that rule, since his only purpose was to hijack my diary entry and come up alphabetically before me in google, to get people to join Yahoo, instead of read the details of the real fraud that happened.
raph, I just came up with a great idea (spawned by the wonderful macros in The Everything Engine (prominently used on PerlMonks). Can we get a <diary>138</diary> tag pair here to link to older diary entries, instead of directly linking to them?
Other News..
E and I went out the other night and caught up with an old friend of mine from CT that I hadn’t seen in a few years. It was good to catch up and get out of the house for a bit.
I’ve been rebuilding boxes here, trying to get things set up for the SourceFubar scale-up. Lots of new neat stuff in store.. stay tuned!
I’ve also been spending a lot of time cranking out more perl code than I can shake two sticks at. I’ve finally gotten my updated copy of Programming Perl 3rd ed., aka “the Camel book”. My copy was 9 years old, and is quite out of date, given current concepts. I also picked up Perl & LWP to help with my current projects (spiders, screen scraping, lots and lots of HTML parsing). I also updated my copy of the C Primer Plus, another Waite Group gem. Mine was 2 editions too old. It’s interesting to walk through some old code and see how much you can squeeze out of it. Code reduction is really a wonderful thing, as long as it doesn’t slip into obfuscation. I managed to take 170 lines of perl in a CGI I wrote recently, and compress it down to 8 lines of code instead.
foreach my $line (@lines) {
$line =~ /@/ or next; # skip things without an @
$line =~ /([wx80-xFF]+)s([wx80-xFF]+)s<(.*?@.*?)>/g or next;
my ($fname, $lname, $addr) = ($1, $2, $3);
$addr =~ s/@/@/g;
$addr =~ s/././g;
print div({-style=>'float: left; text-align: left;'},
"$fname $lname");
print div({-style=>'text-align: right;'},
"<a href="mailto:$addr">$addr</a>");
}
This little gem actually is the tail end of a sub that parses the Plucker CREDITS file for names and emails listed therein, and obfuscates their email addresses to thwart spam harvesting engines, then wraps the code into some very pretty HTML that is shown to the user. It looks like this after these 8 lines are written out. The problem was that perl can’t natively regex unicode/UTF-8 characters as “words” when they contain non-[a-Z][0-9] in them. Sorting them by that is a whole other issue untouched yet.
{kind=link}
More to come on these fronts soon..
Employment
Status: None, 290 days. I got so bored looking for work and finding none, I wrote a script that I wrapped in an iframe on my my PerlMonks home node that calculates how long I’ve been out of work:
<script language="JavaScript">
var today = new Date();
var stdate = new Date("Nov 16, 2001")
var msPerDay = 24 * 60 * 60 * 1000;
var days = ( today.getTime() - stdate.getTime() ) / msPerDay;
days = Math.round(days);
document.write("Status: Unemployed<br />Duration: " + days + " days");
</script>
pilot-link 0.11.2 and abusive Web Spiders
Tags: googlepilot-link 0.11.2
- Just released 0.11.2 a few minutes ago, with several critical bugfixes, BSD/OS 4.3 support, and now with a first pass at FreeBSD and OSX native USB device support. Now it’s time to walk through the code with lclint() and valgrind and see what else I can squeeze out.
Whew. 3 releases in a less than a month, all with a faulty laptop limping along during the process.
Now back to my new Plucker website design and email-only interface to Plucker. Seems there’s a few bugs in Config::Simple that I have to work around right now. I have some neat remote directory rendering code in the new design too, and much more interactivity.
{kind=link}
I hope this brings us a larger userbase, and a community willing to support our efforts.
“No soup for you, google, permanently!”
Due to excessive abuse from google’s spiders, I have now permanently blocked their entire netblock from every single machine that I maintain… which is quite a few. I just removed the iptables rules I had on one production machine, thus unblocking them, and almost immediately 40 concurrent instances of their spider slammed directly into my ViewCVS and Chora instance, going after every single file, version, diff, query, and view linked from there (about 20 projects), completely ignoring robots.txt in the process.
No more for them. Buh-bye.
Employment
-
Status: None, 263 days.
The Wonderful World of Javascript
Tags: google, syncSun Jun 17 19:04:32 PDT 2001
The Wonderful World of Javascript
I started thinking about a way to take a visible page in a browser, and configure some Plucker parameters on that page, and then have it gathered for you, or have the values build a home.html file for you, so you can Pluck that page at your next frequency.
I’ve never done Javascript programming before (can I really call it that?), but here’s what I have so far after about 2 hours of tinkering (it’s a Javascript “popup” wizard walkthrough sort of thing), which will prompt for the URL (it snarfs it from the current page), an expiration time on the cookie (defaults to 1 day), and then the maxdepth of that URL, and sets two local cookies for those values. When it’s all working (or I hit the string length limit on bookmark Location fields), it will walk the user through the full
gamut of settings for that URL.
javascript:q7Hm8=prompt('This webpage has ' + document.links.length + ' links.
Below is the URL of the current webpage. We can now store this value in a
local cookie on your machine. Once your selected Plucker parameters are set,
we can then create a home.html file for you with these parameters. ',location.href);
if(q7Hm8!=null) {
// Prompt for two separate vals
// which will be stored in two
// cookies on the local machine
pVj5D=86400000*prompt('Expires in...(days)','1');
m3xD=prompt('How deep would you like to gather' +
location.href,'1');
// Prompt for the maxdepth value here
1m4g3s=prompt('How deep would you like to gather' +
location.href,'1');
dT9v=new Date;dT9v.setTime(dT9v.getTime()+pVj5D);
// Store the first cookie (URL)
void(document.cookie='PluckerURL='+escape(q7Hm8)+';
expires='+dT9v.toGMTString());
// Store the second cookie (maxdepth)
void(document.cookie='PluckerMaxdepth=
'+escape(m3xD)+';
expires='+dT9v.toGMTString());}else{void(null)
}
So far, this works, and properly sets the cookies. Why do I want to do this in a Javascript fashion? because my goal
here is to make a Plucker “bookmarklet” that most users can use to ease their pain of Plucker configuration
and sync’ing.
An example of how it can be used (for this current page) is here
Reading the cookies back is a bit simpler. I won’t bore you with the code, but it allows me to do some interesting things with it. The problem with Javascript is that I can’t launch a local client application (plucker-build in this example, which is used to actually gather the content itself), nor can I write to a local configuration file. I can, however, put the data in a popup browser window, and have the user do a SaveAs from the menu on that window. It’s not the best solution, but short of having to write several different plugins for each architecture, it will work for the moment.
I’m still trying to find out if Javascript has checkbox and <option select…> type of elements so I can make a real application out of this, in a client-side popup dialog “wizard” thingy.
Why am I not doing this fully in a webpage-style application? Because then you lose focus of the webpage you’re on that you want to Pluck, and this must run client-side. I suppose I could make a webpage that contained similar code, and then submitted the URL to my server for final parsing and gathering, but my server doesn’t have the bandwidth for that right now.
This all started from my original search
google bookmarklet. You can click on it and it will pop up an entry dialog, or you can highlight words on the webpage, and click on it (go ahead, try it) and it will send that highlighted text to google as the search criteria.
I started playing a bit, and came up with another weird one to translate
the current webpage into German (or any other language)
Mantis
The bugtracker is up. Currently supports Plucker, pilot-link, pilot-mailsync, POSE, and a few other projects. I made some cosmetic changes to the layout, and cleaned up some of the PHP code. I’m trying to learn the language, but it’s slow going. Worked for a year with rasmus, and didn’t even use the language once for anything production. EEP!
As the Task List Turns… (unordered)
- Embedded Linux Course, tightening deadlines, scope creep.
- Plucker Bookmark Assistant needs a version update and will begin handling IE as well as Netscape and Mozilla bookmarks. I don’t know what format Konqueror uses, or some of the other browsers, but I can support them too, in time. I found URI::Bookmark which may help a bit.
- The Plucker Perl Spider needs a revisit, and an update. Hasn’t been touched in 11 months. EEP! I have all new ideas for it.
- pilot-link 0.9.5 needs to be released. I wish we could get the final parts of that Ralf’s USB sync fixes pushed in.
- Update the main gnu-designs webpage. I have a new design idea here that I’m tinkering with.
- Chest x-ray.
- …buncha other things…
It’s been a busy Sunday. This week promises to be incredibly productive for me. I still have to be cranking basically 26 pages a day out of this Embedded Linux Course.
My hands hurt.