For anyone using Instagram, Pinterest or similar social media sites, they will often auto-refresh their page to increase ads, impressions and engagement, which is annoying if you’re trying to read content, search a product or just maintain your context.
Open a new browser tab, do a search, close the tab, and your already-open Pinterest tab refreshes on you, losing your position where you were just moments before.
This is most apparent when you’re reading on a mobile device, lock your phone, and then unlock it a minute later. The page reloads, refreshes and you lose where you were just a minute prior. There’s no way to get back, because there’s no “view history” of those moments.
So I decided to “fix the glitch” with a browser userscript, using ViolentMonkey in my case on Brave, Chrome and Firefox.
This specifically tries 5 different methods of auto-refresh, not just scraping page content and injecting or redacting CSS classes. It’s been working flawlessly for me for about a week.
I’ve been a long-time subscriber of Evernote, 15+ years, with hundreds of notebooks, thousands of notes. When they went off the deep end and increased their subscription pricing by 217%, I ended my long history with them.
I moved all of my Evernote notes and notebooks into Joplin, and used that for the last couple of years as a generalized, hierarchical capture system. Many of my friends in the productivity space recommended I consider Obsidian, but until very recently it wasn’t free, and carried a $50/year subscription fee (yes, for everyone who used it for more than just personal use). It was, and continues to be, commercial software.
I had no problems with Joplin, but it was ‘plain’, and wasn’t very extensible in the rich ways I needed to link my notes together, much like I use Xmind for mind mapping.
So I jumped over to Obsidian, and imported all of my Joplin notes. Well, “imported” is the wrong word here, since it was just a tree of Markdown files, I exported from Joplin and moved that tree into the Obsidian data directory.
The next challenge was finding the right plugins to extend the capability of Obsidian to help me with my day-to-day workflow. I found a dozen useful plugins that I’m now using, including the Kikijiki Habit Tracker plugin I’m using for the habit tracker I built tonight. There are plugins for JIRA, Github, Amazon Kindle book highlights, Calendar, Kanban, Mermaid Charts, Tasks and many more.
I started using Dataview and Templater to build a custom Daily Journal page, with some dynamic elements, and soon realized the power of Dataview, so had a play with its visualizations, and built this little Habit Progress tracker around Kikijiki’s plugin:
The resulting rendering of this progress tracker looks like this:
The code is quite simple, just add this to your page of choice:
It will build a dynamic inventory of your defined habits, using the ‘#habit/Thing’ structure provided by Kikijiki as tags on each day’s Daily Journal page. My pages are titled with the format ‘YYYY-MM-DD’, and it parses those inside the ‘Daily Journal’ folder. You may need to alter the code if your pages are in a different place or have a different name.
Suggestions, comments, fixes or anything else you think would improve this are welcome!
If anyone uses Pinterest on a regular basis, you might noticed they recently changed their interface for the first time in just about a decade.
Previously, when you clicked on any image, it would highlight the image and allow you to “Visit Site” if it was linked from that image. Hitting [Esc] would then bring you back to the previous page, the page you came from before you clicked on the image.
Now they’ve update the UI and made it so you need to mouse over the image, and click a back arrow button to go back to the previous page. This is unnecessary and annoying, and breaks common web paradigms.
So I fixed it, with a simple ViolentMonkey/Greasemonkey browser add-on:
// ==UserScript==// @name Pinterest: Escape ? Back// @namespace https://pinterest.com/// @version 1.4// @description Press Esc on Pinterest to go back in history// @match https://*.pinterest.com/*// @grant none// @run-at document-end// ==/UserScript==(function() {'use strict';document.addEventListener('keydown',function(event){if(event.key==='Escape'&&!event.defaultPrevented){varbackButton=document.querySelector('button[data-test-id="back-icon-button"]');if(backButton){backButton.click(); } else {history.back(); } } });})();
This now works as expected, and you don’t need to have your hand on the mouse or mouse around to find that back button.
Sometimes the simplest of solutions is all that’s required.
There have been dozens and dozens of posts attempting plenty of weird, unsupportable hacks and workarounds to get ADS working under the ARM cores used by the Apple M1/M2 chipsets. You need a few dependencies installed and configured to get this working, and Rosetta2 does not work in this situation.
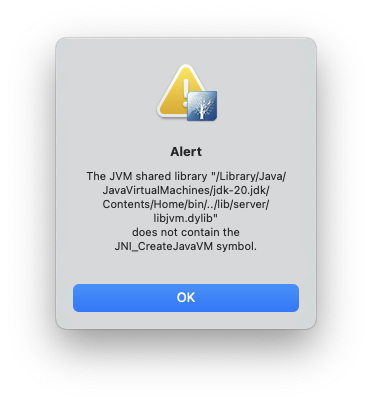
Simply installing Apache Directory Studio from their download page or brew, will result in the following error message when you try to launch it:
This is because the version of Java installed via the OS or from Oracle’s own download page, will not work when it’s the native ARM or aarch64 version.
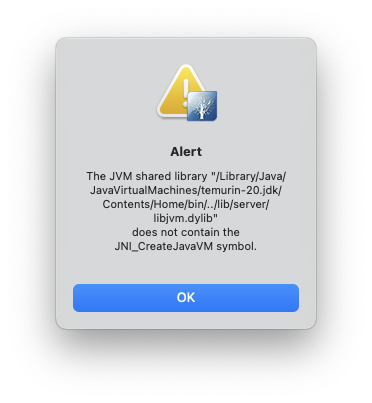
There are many posts that include installing the version of Java from temurin but that too, will give you the wrong version of the JDK to make this work.
brew install --cask temurin
You need at least Java version 11 in order to run Apache Directory Studio, but version 20 will also work, with the steps here.
Also, editing the path in the Info.plist in /Applications/ApacheDirectoryStudio.app/Contents/Info.plist to point to the temurin JDK, will also fail.
There’s an XML block at the bottom of the file that implies you can just point to a different java version you have installed and it will use that. It does, but then crashes with the following dialog, even with the temurin version installed:
<!-- to use a specific Java version (instead of the platform's default) uncomment one of the following options, or add a VM found via $/usr/libexec/java_home -V
<string>-vm</string><string>/System/Library/Java/JavaVirtualMachines/1.6.0.jdk/Contents/Commands/java</string>
<string>-vm</string><string>/Library/Java/JavaVirtualMachines/1.8.0.jdk/Contents/Home/bin/java</string>
-->
To see the versions of Java you may have installed, you can run:
Ok, enough of the context of the failures… let’s get on to fixing this. You can leave the line you edited into your Contents/Info.plist and let’s get the right version of the JDK installed. The version we install will just replace the version in that same directory, and you won’t need to change it (unless you get a different version of Java in these steps).
Even the Oracle installer refuses to continue when using the x86_64 version:
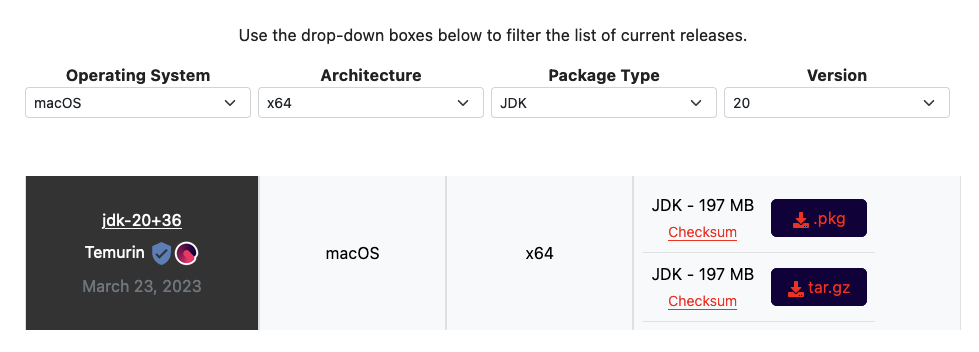
Instead of installing temurn using brew reinstall --cask temurin, you’ll want to visit the Adoptium Temurin download page and grab the version for x86_64, not aarch64, as you normally would get with brew or the Oracle downloads.
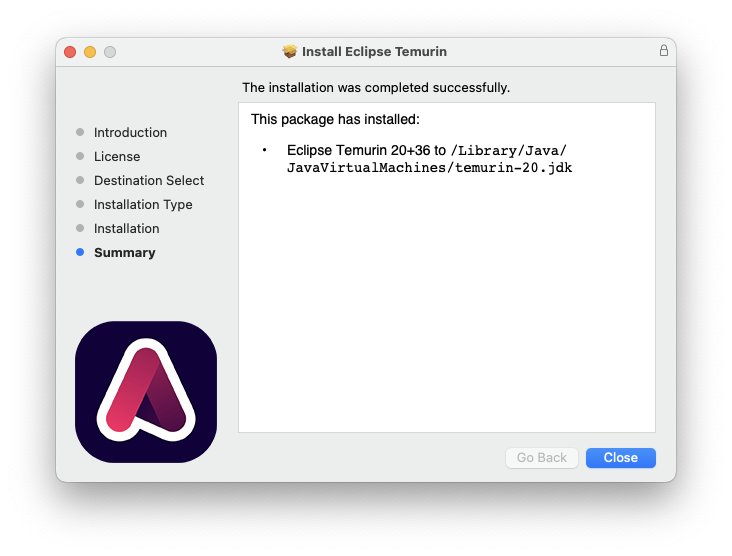
Once you download the x86_64 version of Temurin, it will install cleanly.
Now you can run ApacheDirectoryStudio directly from /Applications or your Terminal, and it will work!
This question has been asked many dozens of times for the last several years, and to-date, has not been solved in the core project itself. There were many attempts, hacks and workarounds, but nothing really supportable.
Let’s say you have two devices, a Personal phone and a Work phone, each running Signal. You want to be able to load one app and have conversations that span both devices. That is, converse with work colleagues and also converse with personal colleagues, from one desktop.
Today, you can’t. Well, not without some additional setup to do so.
To make this work, you’ll need to create a separate data directory for each “profile” you intend to use, and then configure Signal to refer to it when launching them. You can then tie these to a launcher or icon if you wish, in your favorite OS of choice (Linux and macOS are mine, macOS and Windows for others).
Your normal Signal data resides in a directory under your $HOME named ~/.config/Signal by default. Let’s make another to use for testing with your second device. Intuitively, you can name them by the device they are used with, so ~/.config/Signal-iPhone and ~/.config/Signal-Android for example on a POSIX based OS like Linux or macOS. On Windows, this will be stored in C:\Users\You\AppData\Roaming\Signal.
If you’re already using Signal on your desktop, your profile data will just be in the ~/.config/Signal directory, and you don’t need to change it. In fact, renaming it will likely break things until we create these additional profiles. Create a second directory at the same level as the existing one, for use with that second profile.
Now we need to launch Signal from the shell (Terminal in macOS, Command Prompt in Windows), and run it as follows:
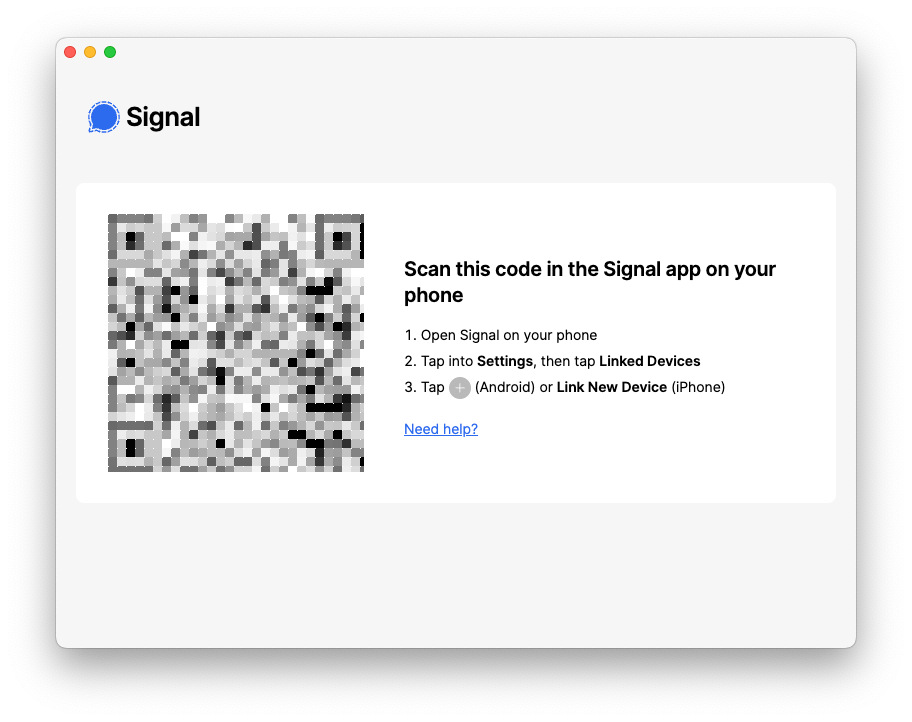
This should prompt you to scan a QR code with your phone, to link the two devices, similar to the following:
On your mobile device, go to Settings ? Linked Devices, and scan that QR code. It will now pair your phone with this instance of Signal Desktop.
So far, so good. Now while that is synchronizing your data, launch the other instance of Signal with the standard launcher. You should now get two instances of Signal Desktop running, one linked with your original mobile device, and this new instance linked with your second mobile device.
Ta-da! You did it.
Now let’s codify these changes into their own respective launchers/icons, so you don’t have to use the shell/Terminal/Command Prompt to do this each time.
On Linux, just create a launcher using your window manager that sets those commandline args as the default.
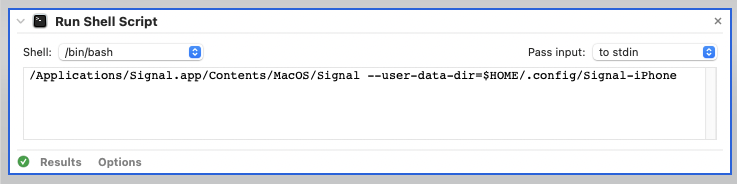
On macOS, you can create a new launcher for Signal with Automator, by choosing “Run Shell Script” from the Workflow menu. Double-click that, and a window will open to the right, allowing you to type in your shell commands. Mine is as follows, just like we ran from Terminal:
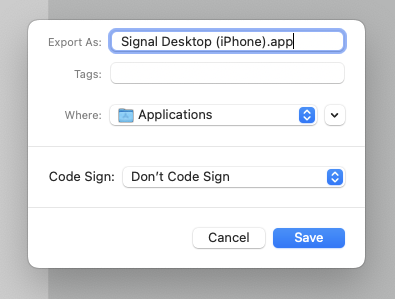
Click “Run” in the upper-right, to ensure it does indeed run Signal Desktop with your second (new) profile correctly. If it does, you can save it as a “Workflow” or an “Application”. I chose the latter, which looks like this:
Now you have your intended commands tied to an application launcher, which can be put into your Dock or other launcher location.
On Windows, you’ll need to create a new desktop shortcut by going to Preferences, and change the target to: C:\Users\You\AppData\Local\Programs\signal-desktop\Signal.exe --user-data-dir=C:\Users\You\AppData\Roaming\Signal-iPhone. You can choose any icon you wish to adorn this shortcut with.
That’s it! You now have a multi-Signal Desktop solution (that is, until the upstream project adds profile support to a newer release).
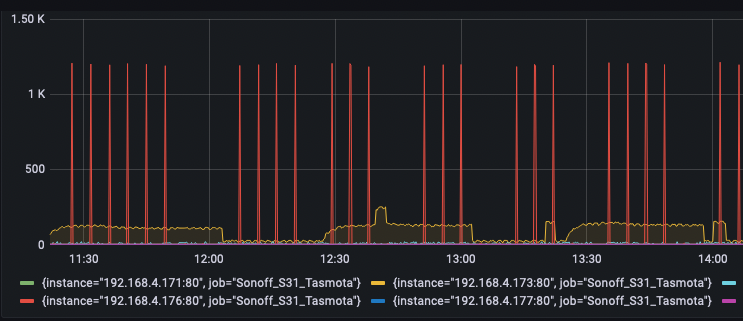
This project was a fun one. I run a lot of devices here, currently 80 according to my network reports, and many of those devices are configured to export their data, status, metrics to a /metrics endpoint that I pull with Prometheus (via prometheus-node-exporter) and then push to Grafana, so I can see fun, pretty graphs of the metrics.
These metrics range from the fan speed, thermal sensors on my laptop, to the ingress/egress packets across my network switch ports to the number of activations per-minute of my basement sump pump plugged into a smart plug, and dozens of other datpoints.
The smart plugs I’m currently using are Sonoff S31 smart plugs (specifically those in this link, because the ZigBee versionsdo not work with Tasmota firmware). Make sure you get the right version! You can use any plug or device that is already running the Tasmota firmware.
This HOWTO does not go into detail about how to dismantle your plug and reflash it with Tasmota. The S31 plugs make this trivially easy, solder-free, compared to many other plugs on the market that require much more dismantling or re-soldering pins.
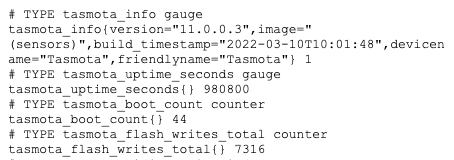
These plugs by default, can measure current coming across the terminals, and give me a lot more data about what’s plugged into them. This data can be exported and made visible in Grafana, but not by default. This HOWTO will show you how to rebuild the Tasmota firmware (very easily), and add that capability.
There’s a few quick pre-requisites:
Download Visual Studio Code. You can download the version directly from Microsoft, or you can use the VSCodium version, which is exactly the same bytes, but compiled without the “phone-home” telemetry and monitoring that Microsoft is known for building into their products. I chose the latter. Functionally, they’re identical.
Download the Platform IO extension for VSCode. Other tutorials describe searching for this from within vscode, but that no longer works. You’ll want to go straight to the Version History tab and click the “Download” link next to the latest version on the right side.
Download the Microsoft CPP Tools package in the same way you did for Platform IO in the previous step (choose “Version History” and click “Download” on the right side). The difference here, is you’ll need to be sure you choose the one specific to the platform you’re building Tasmota on. In my case, I’ll be building it on an Apple Silicon M1 MacBook, so I chose that version:
Clone the Tasmota firmware repository from Github, using using git clone https://github.com/arendst/Tasmota to some local project directory.
Once you have those 3 pieces downloaded, you can start configuring the build environment and building out Tasmota. Here’s how!
Launch vscode (on whichever platform you’re using, it supports all of them).
Bring up your “Extensions” side-panel. On macOS for example, this is done with Shift+Cmd+X. On other environments, the shortcut may be different.
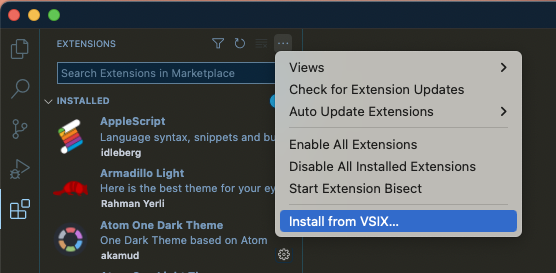
In the upper-right corner of the extensions side-panel, click the 3-dot menu, and choose “Install from VSIX” at the bottom, as shown here:
Choose the location where you downloaded the platformio.platformio-ide-2.4.3.vsix file, and install that. Do the same for the ms-vscode.cpptools-1.9.6@darwin-arm64.vsix package you downloaded.
After installing, you may be asked to restart vscodium. Go ahead and do that anyway, even if you’re not asked. When you do, you’ll probably notice several other, supplementary packages being installed to support this package.
When I did, I got a weird message that my chosen version of the CPP tools was not correct for my platform (it was correct), so just ignore that if you’re on Apple Silicon, and proceed anyway.
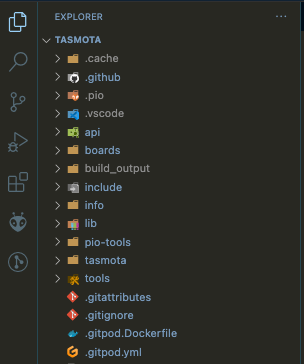
We now need to open up the project directory of the git clone you pulled in Step 4 of the Pre-requisites section above, so it appears as your current project in the File Browser hierarchy:
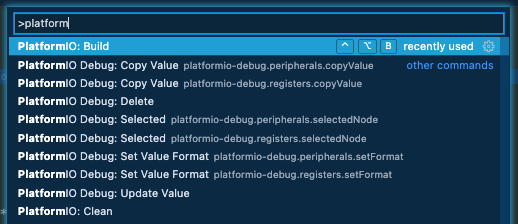
From here, you wan to go to your “Command Palette” in vscode (Shift+Cmd+P on macOS, your key shortcut may vary, but it’s under the “View” menu). And type ‘platform’, until you see “PlatformIO Build”, which should show you something like this:
Now choose that, and let it build to completion. It should be successful, as we haven’t changed anything at all yet. We’re just making sure the basic toolchain works as expected, unaltered. If you got this far, we’re almost done!
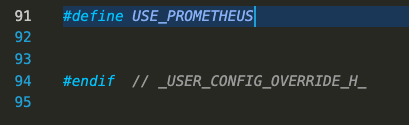
In the Explorer sidebar, navigate down to the tasmota directory inside the project directory (so Tasmota/tasmota) and inside that directory, you’ll find a file called user_config_override.h. Open that file in the vscode editor and scroll to the bottom. We’re going to add 1 line to this file just before the last line of the file and save it: #define USE_PROMETHEUS
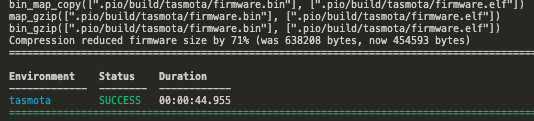
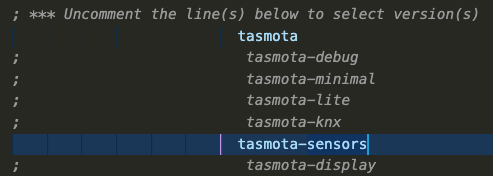
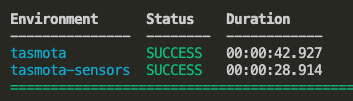
We also need to choose which firmware we’re going to rebuild with this Prometheus support. In the case of my S31 smart plugs, that’s going to be the ‘sensors’ firmware version. That configuration is found in the file called platformio_override.ini in the root of the Tasmota project tree. There is also a sample file there you can use for other options. Open that file in the vscode editor window and uncomment (remove the ; from the line) the firmware you’re building. After the edits, that file should look like the following: You can uncomment as many firmware types as you want, and they’ll be built simultaneously: You can find the completed firmware builds in the Tasmota/build_output/firmware directory of the tree.
Now you can upload that firmware to your smart plug or other device, and you’ll then have a /metrics endpoint exposed with some useful data, which you can point your Prometheus configuration at, to query that data on your interval.
Now go have fun graphing those metrics.. I sure did!
There are quite a few posts out there describing some very odd methods to copy LXD containers from host to host, including shipping snapshots and tarballs of the container’s data directory around.
Those instructions are wrong. Don’t follow them.
The correct, and clean way to do this, is to configure your LXD hosts to talk to each other, and simply copy the containers between them. There’s a few reasons to use this approach:
It’s more secure, using a secure transport, and proper authorization
It doesn’t clutter up the source and destination with 2-3x the container size to create a temporary tarball which gets shipped around between hosts
It allows you to start moving towards using LXD clusters, which is a “Good Thing(tm)”
It relies purely on LXD concepts and built-ins, not external apps, programs or workarounds
So let’s get to it.
On LXD host_1, you can create a container or VM, as follows:
On this same LXD host, we can now configure a “remote” LXD host for it to speak to:
$lxcremoteaddhost_2
You will be prompted to accept the host’s fingerprint, and alternately a connection password to authorize the addition. Once added, you can verify it with:
$lxcremotelist+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| NAME | URL | PROTOCOL | AUTHTYPE | PUBLIC | STATIC | GLOBAL |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| host_2 | https://host_2:8443 | lxd | tls | NO | NO | NO |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| images | https://images.linuxcontainers.org | simplestreams | none | YES | NO | NO |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| local (current) | unix:// | lxd | fileaccess | NO | YES | NO |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| ubuntu | https://cloud-images.ubuntu.com/releases | simplestreams | none | YES | YES | NO |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+| ubuntu-daily | https://cloud-images.ubuntu.com/daily | simplestreams | none | YES | YES | NO |+-----------------+------------------------------------------+---------------+-------------+--------+--------+--------+
Before we do anything to the running VM (vm1) and container (c1), we want to take a snapshot to ensure that any trouble we have, can be restored safely from that snapshot.
$lxcstopvm1$lxcstopc1$lxcsnapshotvm12022-03-12-snapshot# any name will do$lxcsnapshotc12022-03-12-snapshot
We always confirm our changes, especially where it relates to data preservation:
$lxcinfovm1Name:vm1Status:STOPPEDType:virtual-machineArchitecture:x86_64Created:2022/03/1219:35ESTLastUsed:2022/03/1219:36ESTSnapshots:+---------------------+----------------------+------------+----------+| NAME | TAKENAT | EXPIRESAT | STATEFUL |+---------------------+----------------------+------------+----------+| 2022-03-12-snapshot | 2022/03/1219:44EST | | NO |+---------------------+----------------------+------------+----------+
Now we can start those back up:
$lxcstartvm1c1
From here, we can now copy the snapshots we just made on LXD host_1 to LXD host_2:
On host_2, you can see that the vm1 we created on host_1, is now copied to host_2, and remains in a ‘STOPPED‘ state:
$lxclist+--------------------+---------+-----------------------+------+-----------------+-----------+| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |+--------------------+---------+-----------------------+------+-----------------+-----------+| vm1 | STOPPED | | | VIRTUAL-MACHINE | 0 |+--------------------+---------+-----------------------+------+-----------------+-----------+
You can now start that VM, and have it running there, on host_2:
$lxcstartvm1
Note: host_2 may have live on the same subnet as host_1, which means it may need a new IP address, if the original container is still running on host_1.
You will need to stop the container on host_1 and either give host_1 a new IP address, or start up host_2, and give it a new IP address. The two containers on the same L2 network will conflict, and your DHCP server will refuse to hand out a lease to the second one requesting it.
There are a couple of ways to do this:
Give the container a static IP address. When you copy it to the second host, give it a different static IP address there, or
If these containers will request a DHCP lease, you can remove /etc/machine-id and generate a new one by running systemd-machine-id-setup. With a new machine-id, the container will appear to be a new machine to your DHCP server, and it will hand out a second lease to the second container.
With the container(s) copied from host to host, and their networking reconfigured to fit your LAN/network topology, you should have them running.
This is a stopgap though, as this isn’t an HA setup. If you truly want to have resilience, you should set up a LXD cluster between both LXD hosts, and then you can see/create/move/migrate containers between the hosts on-demand, seamlessly. When you configure those LXD servers to use shared storage (common to both LXD hosts in this case), the containers will survive a full outage of one or the other LXD host.
Note: I work for Canonical, we make Ubuntu (among dozens of other products)
In many cases, you want to be able to upgrade your Ubuntu release between different versions over time. There are many tools that allow you to do this seamlessly and without loss of function or data. One such tool is called do-release-upgrade, found in the ubuntu-release-upgrader-core package. You can move between supported LTS releases, as well as development releases.
What’s missing, is the ability to roll back from a release, for example when an application or library you rely on, has no support for the newer version of the OS release. With ZFS root on Ubuntu, you can create a snapshot before upgrading and roll back that snapshot when things do not go to plan. With VMs and containers, taking snapshots and reverting those becomes even easier.
But let’s stick with standard tools and supported mechanisms for the moment. I just did this minutes before writing this blog post, and have done this dozens of times in the past.
I have a working, Ubuntu Focal Fossa (20.04) baremetal machine I use as a reproducer for tricky customer issues using MAAS (Canonical’s baremetal provisioning product). In some cases, I need to move between MAAS versions to execute those tests, and they have to be done on baremetal, because VMs and containers can’t model the same topology.
MAAS has matured in its version support and newer versions of MAAS no longer support older versions of Ubuntu. For example, Ubuntu Bionic Beaver (18.04) supports MAAS versions up to version 2.8, but to consume a newer version of MAAS (2.9, 3.0, 3.1), you have to upgrade to Focal (20.04). Once the machine has been upgraded and running MAAS 3.1 on 20.04, you can’t test issues reported against 2.8 or Bionic. Rolling back becomes important.
So let’s do that!
First and most-important, is to make sure you have no broken packages, half-installed .deb packages or weird/custom PPAs. You can use ppa-purge to get rid of those third-party PPAs (you can put them back later), but for now, let’s just move them out of the way:
rename.ullistorig/etc/apt/sources.list.d/*.list
Note: rename.ul comes from the util-linux package on most Linux distributions.
Now we can wipe out the cached package lists for the current Ubuntu release:
rm/var/lib/apt/lists/*
We also need to transform our sources.list file in /etc/apt/ to point to the previous Ubuntu release. We can either edit the file directly, or make a copy for each release, and refer to them individually. Since I roll forward and back very often, I keep copies of both, and use a symlink to flip between them. That looks like this:
Note: The extension of the original file cannot include the .list extension, or it will be parsed by apt/apt-get. They have to be a different extension, as .list is significant.
For now, I’m rolling back from Focal to Bionic, so this is the correct link.
We also need to make sure we define a preference to permit us to roll back. We do this with setting the package priority in a file that lives in the /etc/apt/preferences.d directory:
Create a file in there called rollback.pref with the following contents. You can use the same logic as I did with the sources.list symlink above.
Note: The extension of the original file cannot include the .pref extension, or it will be parsed by apt, and that’s not what you want.
Package:*Pin:releasea=BionicPin-Priority:1001
This indicates that the package priority for the packages with the series ‘Bionic’ have a higher priority than the currently installed versions of those same/similar packages.
Now we can update those package lists with apt update or apt-get update as you prefer. Once the package lists have been updated, hopefully without any errors, we can execute the following to downgrade all of them to the versions we need:
apt-get-fyuupgrade--allow-downgrades
Note, this may not be foolproof, depending on what’s running on your system and how you used those packages. You may need to make note of some conflicts and do some removal/reinstall of those conflicting package to work around some up/down dependency issues, but that should be minimal. Here’s one example:
# apt-get -fyu dist-upgrade --allow-downgradesReadingpackagelists...DoneBuildingdependencytreeReadingstateinformation...DoneCalculatingupgrade...DoneHmm,seemsliketheAutoRemoverdestroyedsomethingwhichreallyshouldn't happen. Please file a bug report against apt.The following information may help to resolve the situation:The following packages have unmet dependencies: f2fs-tools : Depends: libf2fs0 (= 1.10.0-1) but it is not going to be installedE: Internal Error, AutoRemover broke stuff
To resolve this, I can do something like the following:
If you want to be pedantic and ensure your system will definitely boot, you can do two more things before that final reboot.
sudoupdate-initramfs-ukallsudoupdate-grub
And that’s it! Once the packages are cleanly downgraded, you should be able to reboot the machine back into the previous Ubuntu OS release.
Update: I just noticed that immediately after my first reboot, there were more packages that needed to be downgraded. I simply re-ran the downgrade again, and these were updated to the previous versions:
apt-get-fyudist-upgrade--allow-downgrades
I also ran the following, to remove unneeded packages after that last, clean downgrade step:
This was a challenge/goal of mine and true to form, I rarely give up until I’ve figured something out, or coded a workaround. As Mark Rober so eloquently said, 2m10s into this video about the NICEST Car Horn Ever:
“The good news is that as an engineer, if something isn’t exactly how you want it… you just make it exactly how you want it.”
Some points straight from the start:
The GoPro does not support connecting TO WiFi networks. Full stop. Period. It can’t be a wireless client, only an AP.
The hardware is fully capable of connecting to existing WiFi networks but GoPro restricts this, and there’s no foreseeable way around it without hacking into the firmware and reflashing it with a replacement.
You can connect TO the GoPro as it presents its own WiFi network, but you cannot connect your GoPro to any existing WiFi network in range.
A $12 smart plug can connect to an existing WiFi network, but a $400 action cam from GoPro cannot. #facepalm
To connect the GoPro via HDMI directly, you need their $79 Media Mod hardware.
It’s essentially a frame that wraps around the GoPro, and exposes USB-C, micro-HDMI and an audio port for the device.
All of these are accessible via the single USB Type-C port that the Media Mod docks into. A USB Type-C to micro-HDMI adapter will not work when plugged into the bare GoPro USB Type-C port.
I tried 3 different models, they were all rejected and ignored.
GoPro Hero 5, 6 and 7 models supported native HDMI out. The Hero 8, 9 and 10 do not.
You need the additional Media Mod to get native HDMI out.
Anything greater than 1080p will require HDMI out.
So let’s dive in and get this working!
First thing you’ll need, is a USB cable. This can be a native USB Type-C to USB Type-C cable, or USB Type-C to USB Type-A, whatever your specific hardware (laptop or PC) requires.
You’ll want this cable to be relatively long, if you’re using this as a webcam, so you can position it where you need it, without being limited by cable length. There are an infinite number of choices and colors for these cables on Amazon and other retailers.
Just make sure you get a good quality, shielded cable for this purpose.
Once you have that, you’ll need to open up the battery door and pop that off, or, alternatively you can leave it ajar, with the battery inserted. I don’t like the door hanging half-off at a 45-degree angle, so I pried mine off. Since I also own the Media Mod, this was something I’ve already done 100 times.
To remove the door, you just open the door all the way until it won’t go any higher, than you give it gentle twist from front of camera to back, and it will pop off the hinge. If you’re used to how a Garmin watch band is removed from the watch face, it’s similar to that.
Next, you’ll want to go into the GoPro settings, and make sure the connection type is not “MTP” (used when mounting your GoPro as a “storage” device to retrieve photos, videos from your device. We’re not doing that here, so go the menus and swipe up, go to Settings ? Connections ? USB Connection ? GoPro Connect.
Now let’s make a quick change to your host’s networking to support giving this device a DHCP address when you connect it to your machine. To do that, you’ll use one of the following constructs:
If using netplan,. your configuration should look something like this, in a new file called /etc/netplan/02-gopro.yaml:
If you’re using the legacy ifupdown style configuration, you’ll want to add the following to /etc/network/interfaces (or /etc/sysconfig/network for RPM-based distributions):
autousb0ifaceusb0inetdhcp
To activate that, you can do a sudo netplan apply and it will render that configuration and restart systemd-networkd for you to acquire a DHCP lease when the camera is plugged in via USB. For legacy ifupdown, you’ll want to just restart your networking service with systemctl or service.
When you do plug your camera in, you should see something like the following in dmesg:
[20434.698644] usb 1-1.4.2: new high-speed USB device number 24 using xhci_hcd[20434.804279] usb 1-1.4.2: New USB device found, idVendor=2672, idProduct=0052, bcdDevice= 4.04[20434.804283] usb 1-1.4.2: New USB device strings: Mfr=1, Product=2, SerialNumber=3[20434.804284] usb 1-1.4.2: Product: HERO9[20434.804285] usb 1-1.4.2: Manufacturer: GoPro[20434.804285] usb 1-1.4.2: SerialNumber: Cxxxxxxxxxx123[20434.811891] cdc_ether 1-1.4.2:1.0 usb0: register 'cdc_ether' at usb-0000:00:14.0-1.4.2, CDC Ethernet Device, 22:68:e2:ca:88:37
If you plugged in your camera and netplan/ifupdown assigned it a DHCP lease, you should now see something like:
Now we need to check out an upstream Github repository that includes some helper scripts/code to bring this camera online, attach a running ffmpeg process to it, and begin streaming it to a device in /dev/.
If you go into that newly cloned repository and run the following command, you should see a new device get created that you can talk to. Make sure to change the IP to the one you observed when running the ip a s usb0 command above (bolded above and below for emphasis).
Further down in the output, just before it begins to launch ffmpeg and start encoding the stream, you should see two lines that look like this:
[swscaler @ 0x56073e173740] deprecated pixel format used, make sure you did set range correctlyOutput#0, video4linux2,v4l2, to '/dev/video42':
That /dev/video42 is the important part for your streaming tools. If you use Open Broadcaster Studio (OBS), that’s the camera device you’ll want to connect to when you choose “Video Capture”, when creating a camera in your scene.
If you want to preview/play this stream that ffmpeg is creating for you, you can use mplayer to do that, as follows:
This will open a new, live, preview window you can use to fine-tune your scene, layout and positioning of the camera.
I have my camera sitting on an extremely long microphone boom arm with an extra ‘forearm’ to reach up and over my monitors from behind (many thanks go to ATARABYTE for this idea and the link to the Heron 5ft Articulating Arm Camera Mount [note: affiliate link to give her credit]).
So that’s it!
Once you have the camera on the network with an IP you can route to, you can use the gopro script from Joshua Schmid’s GH repository to create a device that can then be used by ffmpeg or OBS to stream that camera’s feed to other locations.
Keep in mind, there is a subtle 0.5s delay, but it’s not terrible. If you’re recording the stream, you can adjust the audio so it lines up in OBS with the latency/delay features. If you’re using this live, I would recommend not using this as a front-facing camera, and only use it as a secondary/backup or overhead cam (my specific use case is as an overhead cam for close-up work).
The GoPro, being an “Action Cam” also does not have autofocus, so anything closer than about 12″, will start to blur out. If you need autofocus, consider using a mirrorless DSLR camera and a decent lens. To connect that to your Linux machine, you can use an Elgato CamLink 4k device. I use this as well, with my main streaming setup, and it works fantastic on Linux, with no drivers or setup required.
With the pandemic continuing and no real end in sight, those of us who work from home are putting in extended hours at work, and extended hours on our computers and office equipment, including our eyes and monitors.
My monitors have started to develop burn-in and ghosting on parts of the screen where I keep common apps running like my browser windows, chat apps and other services.
Modern monitors lack the “degaussing” feature that was popular years ago on older CRT monitors to help remove those ghost images.
Fear not! There’s still a way to help remove ghosting, and it doesn’t involve running a screensaver! You can run an “LCD scrub” behind your windows as you work (or in a cron job, systemd unit or other time-based scheduler). Here’s how!
First, install the xscreensaver-data-extra package from your favorite package archive. In Ubuntu, that’s a simple sudo apt install xscreensaver-data-extra command. Then, run the following one-liner to target your ‘root’ window (Desktop):
This will run the lcdscrub utility in your ‘root’ display, scrubbing the screen behind all of your current windows. Of course, you can close those windows around and make it more effective.
Here’s a quick video showing how this works:
lcdscrub saving my desktop display from ghosting and burn-in
Running this on a regular basis is a good idea, so you can avoid the kind of burn-in that can prematurely age your display. Since it may be difficult (or expensive) to replace monitors with chip and electronic shortages, you’ll want to extend the life as long as you can, before inventory becomes available for replacements.