
HOWTO: Configure Tor + SASL + irc to connect to Freenode
Tags: freenode, identd, irc, linux, nickname, Perl, Python, Tcl, VMware, xchatI fought this problem on the train into the city today, because my MiFi‘s hostname was not correctly reversing to it’s given IP (verified by dig) and Freenode was denying the connection; it looked like this:
Mar 22 06:51:41 * Looking up irc.freenode.net Mar 22 06:51:41 * Connecting to chat.freenode.net (86.65.39.15) port 6667... Mar 22 06:51:42 * Connected. Now logging in... Mar 22 06:51:42 * *** Looking up your hostname... Mar 22 06:51:42 * *** Checking Ident Mar 22 06:51:42 * *** Your forward and reverse DNS do not match, ignoring hostname Mar 22 06:51:55 * *** No Ident response Mar 22 06:51:55 * *** Notice -- You need to identify via SASL to use this server Mar 22 06:51:55 * Closing Link: 166.199.4.113 (SASL access only) Mar 22 06:51:55 * Disconnected (Remote host closed socket). Mar 22 06:52:05 Cycling to next server in Freenode... Mar 22 06:52:05 * Disconnected ().
I wanted to connect, to talk to the folks in #linux, and ask them about another question I had (see newer blog post about fullscreen VMware session for that). This was yet another example of the kind of Yak Shaving I deal with on a daily basis.
At first, I tried installing a few identd daemons, then some of the spoofing identd daemons, then purged them all and decided to try identifying using SASL like it suggested.
I did a few seconds of Google’ing and found a helpful website with a SASL plugin in C. I compiled that, installed it into /usr/lib/xchat/plugins, restarted XChat, and attempted to authenticate and identify using this plugin and the instructions.
If the site goes down, I have local copies of the files you need, just email me.
You’ll need to create a file called cap_sasl.conf and put it in ~/.xchat2/, which includes the following syntax:
/sasl [nickname] [password] FreeNode
So if your nickname (username on Freenode) was ‘foobar‘ and your password was “MyS3cretPas5word“, you’d put the following in that file:
/sasl foobar MyS3cretPas5word FreeNode
If you compiled this correctly and put it in the right place, you can also just issue a simple /help sasl command to get the syntax:
Usage: SASL <login> <password> <network>, enable SASL authentication for given network
When you load up XChat, you should see something like this in the main window (if the plugin works):
Python interface loaded Display amarok loaded, type "/disrok help" for a command list Perl interface loaded Tcl plugin for XChat - Version 1.63 Copyright 2002-2005 Daniel P. Stasinski http://www.scriptkitties.com/tclplugin/ Tcl interface loaded Loading cap_sasl.conf Enabled SASL authentication for FreeNode cap_sasl plugin 0.0.4 loaded
The last two lines are what you’re looking for. Now typing “/sasl” will show you the following:
foobar:MyS3cretPas5word at FreeNode
This too, failed to authenticate me and validate my (incorrect) reverse DNS problem. What I saw was this:
Mar 22 20:24:02 * Looking up irc.freenode.net Mar 22 20:24:05 * Connecting to chat.freenode.net (140.211.167.98) port 6667... Mar 22 20:24:05 * Connected. Now logging in... Mar 22 20:24:05 * *** Looking up your hostname... Mar 22 20:24:05 * *** Checking Ident Mar 22 20:24:06 * *** Couldn't look up your hostname Mar 22 20:24:19 * *** No Ident response Mar 22 20:24:52 * Closing Link: 32.138.186.102 (Connection timed out) Mar 22 20:24:52 * Disconnected (Remote host closed socket). Mar 22 20:25:02 Cycling to next server in Freenode...
I decided to investigate a different solution: Tor!
Read the rest of this entry »
Yak-shaving with my Music and Media collection
Tags: Perl, Python
This particular bit of yak-shaving all started because one of the Amtrak LSA staff asked me if I could write a tool to print out his MP3 collection by Artist, Album and/or Year. This LSA (Lead Service Attendant; they manage the café car) works as a DJ in his off-hours, doing various gigs for weddings and other parties.
So I took 15 minutes while traveling to the office to whip up something in Perl that did just that, and dumped it to a plain text file which I could then reformat in OpenOffice.org and then export as a pretty PDF he could print and hole-punch into his DJ binder. Problem solved, and he was impressed that it only took 15 minutes to cook that up.
And that’s when it started. The yak-shaving.
“yak shaving is what you are doing when you’re doing some stupid, fiddly little task that bears no obvious relationship to what you’re supposed to be working on, but yet a chain of twelve causal relations links what you’re doing to the original meta-task.”
Here’s how it began:
While building that list of Artist/Album/Title/Year, I realized that some of my mp3 files were missing some pieces of information. Some had the years missing, some had the genre mixed up, some were missing the data altogether.
So I went in and started fixing that.
Then I realized that the album art I was storing as “folder.jpg” was missing in some directories, and each time I rebuild my music library via amaoK or iTunes or anything else, I have to go re-fetch those missing album covers from Amazon or other online places.
So I went in and started fixing that too.
To do that, I had to use a Windows tool called Tag Tuner. I’m not a Windows person by any means, but there really is nothing as slick as TagTuner in Linux (yet?). There is kid3, but it lacks some pretty powerful features (but adds its own, like the ability to remove headers from the mp3 files).
I started adding in all of the missing cover art, storing the album art as an actual image file within the APIC field of the ID3v2 MP3 header. Some of the album art required that I scan in the actual covers from the CDs I have that aren’t available anymore, or aren’t online. Some of it was Google’d up, and others were found in other places on the ‘net.
It was (and still is) an enormous task to make sure every piece of the mp3 metadata is correct, album art is intact (including bootlegs, bonus albums, NFR [not for resale] albums and others).
Then I decided to try to “enhance” the Perl script I wrote, by slapping a web front-end on it, so I could sort by Artist, Album, Year, Genre and so on, and export that to a nicely-formatted PDF file for “Shaggy” (the Amtrak LSA/DJ) or myself.
I started down the path of looking into the Apache::MP3 Perl module on CPAN, which looked promising. When I Google’d up some example code, I saw a reference in an obscure Ubuntu forum post that mentioned using an Apache2 module called mod_musicindex, which supersedes Apache::MP3.
I installed and configured that, and found that there were some discrepancies in the configuration, and that some of the values in the default stanzas indicated in several web references on setting up mod_musicindex all pointed to. They were all incorrect. Here’s what was suggested:
Alias /music/ "/Media/Music/mp3/"
<Directory "/Media/Music/mp3/">
AuthType Basic
AuthName "music"
Require group music
Options Indexes MultiViews FollowSymlinks
AllowOverride Indexes
MusicIndex On +Stream +Download +Search -Rss -Tarball
MusicFields title artist length bitrate
MusicPageTitle Media Library
MusicDefaultCss musicindex.css
MusicIndexCache file://tmp/music
MusicDirPerLine 4
MusicIceServer [ice.gnu-designs.com]:8000
MusicCookieLife 300
</Directory>
The problem was that restarting Apache resulted in errors with some of those options. I found a small clue buried in the README for musicindex:
“The MusicIndex Option replaces altogether MusicLister, MusicAllowDownload, MusicAllowStream, MusicAllowSearch, and MusicAllowRss.”
Removing those options and replacing them with their new equivalents solved that problem.
Alias /music/ "/Media/Music/mp3/"
<Directory "/Media/Music/mp3/">
AuthType Basic
AuthName "music"
Require group music
Options Indexes MultiViews FollowSymlinks
AllowOverride Indexes
MusicIndex On +Stream +Download +Search -Rss -Tarball
MusicSortOrder album disc track artist title length bitrate freq filetype filename uri
MusicFields title artist album length bitrate
MusicPageTitle Media Library
MusicDefaultCss musicindex.css
MusicIndexCache file://tmp/music
MusicDirPerLine 4
MusicIceServer [ice.gnu-designs.com]:8000
MusicCookieLife 300
</Directory>
And that worked. But it was deathly slow to render a single directory of only a handful of music files. I tried to eek out more performance, but it was just too slow to be useful.
Then I found a reference in another forum thread of a replacement for mod_musicindex called “edna“, so I decided to download that and give it a try.
edna is a standalone Python script which listens on a port and can present your music collection in a very similar way to mod_musicindex, but it is VERY fast, and has quite a few additional features that mod_musicindex does not provide.
But… it’s Python, and I have a genetic distaste for anything written in that language. I played with it for quite awhile and walked around my music collection with it. One of the limitations of edna that I found (besides being written in Python) was that it required that album art be in a single, separate file stored in the same directory as the mp3 files. Since I painstakingly took the time to store each and every album cover in the mp3 files themselves, this was a no-go for me.
So I went back to mod_musicindex while I kept looking for alternatives. One of the quirks with mod_musicindex that I found, was its rendering of proper unicode characters. I jumped into the #apache IRC channel on Freenode to ask for some guidance with respect to “tricking” the right charset to be used (for example, Björk was showing up as B?ork) and one of the lurkers in #apache asked if I’d ever heard of “Ampache” before. I hadn’t, so I trundled over and installed a copy.
The installation was really clunky and challenging, and I had to go into the code at one point and gut out a check which was throwing an error, because it made assumptions about my Apache setup that were just not valid.
I installed that, configured it, added a “catalog” (what ampache calls a collection of your music) to begin navigating through the interface.
In doing so, I realized that there were still quite a few mp3 flies with the wrong ID3v2 metadata or missing/incorrect album covers.
So that’s where I am now. I’m using a combination of Ampache + TagTuner to go through my entire MP3 collection and “normalizing” all of the data in each file. It’s long and drawn out work, but ultimately beneficial, since I only have to do it once.
And when I get back on the train to NY again and “Shaggy” is working, I can show him this system and see if it would be useful for his own DJ rig or parties.
THAT, is yak shaving in the true sense and spirit of the term.
HOWTO get YouTube video content onto your Apple iPod
Tags: Apple, iPod, Python, video, YouTubeI’m sure you’ve heard of YouTube by now.
YouTube is a video sharing website where users can upload, view and share video clips with other visitors to the site. YouTube was created in mid-February 2005 by three former PayPal employees.
The San Bruno-based service uses Adobe Flash technology to display a wide variety of user-generated video content, including movie clips, TV clips and music videos, as well as amateur content such as video blogging and short original videos. In October 2006, Google Inc. announced that it had reached a deal to acquire the company for US$1.65 billion in Google stock.
In August 2006, The Wall Street Journal published an article revealing that YouTube was hosting about 6.1 million videos (requiring about 45 terabytes of storage space), and had about 500,000 user accounts.
A YouTube search done today reveals more than 83 million videos and many millions of user channels. In fact, there are so many, YouTube no longer lists how many and restricts all searches to only 1,000 results or less.
Not bad for a company that is completely unprofitable and whose revenues being noted as “immaterial” by Google in a regulatory filing. The bandwidth costs to operate YouTube alone are estimated at approximately $1 million a day.
But enough about the numbers and dollars, let’s talk about how to get that content onto your Apple iPod video device!
I find myself with lots of “spare time” around my commutes, waiting for trains, driving, late at night while I turn off my brain and relax and many other places. I’ve collected lots of audiobooks, music streams and videos that I watch and discard from my ipod on a regular basis. A lot of the video content I watch now comes directly from YouTube.
The first thing you’re going to need is a copy of YouTube Downloader. This is a very simple Python script that takes a YouTube URL as input and will download and copy the file to your local system.
There are versions of youtube-dl available to all of the current Linux distributions if you simply install it with your normal packaging tools (yum, aptitude, synaptic, etc.), as well as a detailed guide to installing YouTube Downloader under Windows XP for those stuck on that legacy platform.
That’s step one.
The second step is to grab a current copy of the ffmpeg Video Encoder. Your Linux distribution may have this already, but if not, you can just download the latest source with SVN or Git and build it yourself.
For Windows users, you can either download a compiled version (you’ll need a copy of 7-zip to unpack it), or follow this HOWTO and build your own on Windows from source.
If you’re building this on Linux or Windows, make sure you include libfaac support in your build. This is critical, because iTunes won’t accept the format if it isn’t in MPEG-4 format (or AVI, but AVI files are enormous).
At the very least, use the following options when building ffmpeg from source:
./configure --prefix=/usr --enable-gpl --enable-pthreads
--enable-libvorbis --enable-libtheora
--enable-libgsm --enable-libfaac --enable-libfaad
--enable-liba52 --enable-shared --enable-libschroedinger
--enable-libx264
If you got it right, you should see something similar to the following:
install prefix /usr C compiler gcc .align is power-of-two no ARCH x86_64 (generic) big-endian no MMX enabled yes CMOV enabled no CMOV is fast no EBX available yes EBP available yes gprof enabled no debug symbols yes strip symbols yes optimizations yes static yes shared yes postprocessing support no software scaler enabled no new filter support no filters using lavformat no video hooking yes Imlib2 support no FreeType support yes network support yes IPv6 support yes threading support pthreads SDL support yes Sun medialib support no AVISynth enabled no liba52 support yes liba52 dlopened no libamr-nb support no libamr-wb support no libdc1394 support no libdirac enabled no libfaac enabled yes <--- This is what you want to see libfaad enabled yes libfaad dlopened no libgsm enabled yes libmp3lame enabled no libnut enabled no libschroedinger enabled yes libtheora enabled yes libvorbis enabled yes libx264 enabled yes libxvid enabled no zlib enabled yes bzlib enabled yes
Build it and install it. Now you should have a working ffmpeg encoder.
The third step is to encode the video and lastly, sync it to your iPod.
In this process, I'm going to use the example of "Groovy Dancing Girl" starring "Sophie Merry" from Ireland. She created an Internet sensation with her YouTube video, but now she's become quite famous as a new face on Etam's product lines.
This was a short-enough video to use as an example, but in practice, I'm normally converting 1-2 hour videos found on YouTube for watching on my iPod. Inbox Zero with Merlin Mann is a good example of just such a video.
Let's put all the steps together:
- Download the video using youtube-dl. We're going to pass it the
-l(that's an 'ell', not a 'one') option so we save the video itself with the original title as it appeared on the upstream YouTube URL.
$ /usr/bin/youtube-dl -l http://www.youtube.com/watch?v=Sr2JneittqQ Retrieving video webpage... done. Extracting video title... done. Extracting URL "t" parameter... done. Requesting video file... done. Video data found at http://208.117.254.159/get_video?video_id=Sr2JneittqQ&origin=sjc-v78.sjc.youtube.com &signature=7324C862B157C2C77781B15449C09F83FEBDAC71.89013B87A16736E75BB13B354 A03F528D0CEABFC&ip=65.172.152.98&ipbits=16&expire=1213949408&key=yt1&sver=2 Retrieving video data: 100.0% ( 8.81M of 8.81M) at 85.50k/s ETA 00:00 done. Video data saved to Groovy Dancing Girl-Sr2JneittqQ.flv
- Encode the video using the ffmpeg you just built above:
$ ffmpeg -i Groovy\ Dancing\ Girl-Sr2JneittqQ.flv -threads 4 -b 604k -ac 1 -ab 256k -ar 44100 -vol 500 Groovy\ Dancing\ Girl.mp4 FFmpeg version SVN-r13835, Copyright (c) 2000-2008 Fabrice Bellard, et al. libavutil version: 49.7.0 libavcodec version: 51.57.2 libavformat version: 52.16.0 libavdevice version: 52.0.0 built on Jun 19 2008 22:21:44, gcc: 4.2.3 (Ubuntu 4.2.3-2ubuntu7) Seems stream 0 codec frame rate differs from container frame rate: 1000.00 (1000/1) -> 29.92 (359/12) Input #0, flv, from 'Groovy Dancing Girl-Sr2JneittqQ.flv': Duration: 00:03:42.35, start: 0.000000, bitrate: 56 kb/s Stream #0.0: Video: flv, yuv420p, 320x240, 29.92 tb(r) Stream #0.1: Audio: mp3, 22050 Hz, mono, 56 kb/s Output #0, mp4, to 'Groovy Dancing Girl.mp4': Stream #0.0: Video: mpeg4, yuv420p, 320x240, q=2-31, 604 kb/s, 29.92 tb(c) Stream #0.1: Audio: libfaac, 44100 Hz, mono, 256 kb/s Stream mapping: Stream #0.0 -> #0.0 Stream #0.1 -> #0.1 Press [q] to stop encoding frame= 6654 fps=571 q=2.0 Lsize= 18676kB time=221.63 bitrate= 690.3kbits/s video:16489kB audio:2055kB global headers:0kB muxing overhead 0.708581%This will give you a video called "
Groovy Dancing Girl.mp4", which is of type:VIDEO: [mp4v] 320x240 24bpp 29.917 fps
- Now drag this .mp4 video directly onto your iTunes application window to add it to your Video library, and iTunes will sync it to your iPod the next time you connect. Voila!
If you're solely a Linux user, you can use Songbird (a Mozilla project), or install Amarok (my personal favorite, absolutely blows away iTunes in features).
If you have any questions, contact me or leave your comments here and I'll do my best to help you out.
Good luck!
Funny Ubuntu Error Message of the Day
Tags: linux, Python, UbuntuSorry, command-not-found has crashed! Please file a bug report at:
https://bugs.launchpad.net/ubuntu/+source/command-not-found
Please include the following information with the report:
No module named CommandNotFound
Traceback (most recent call last):
File "/usr/lib/command-not-found", line 10, in
from CommandNotFound import CommandNotFound
ImportError: No module named CommandNotFound
Python version: 2.5.2 final 0 So the command /usr/lib/command-not-found could not find a required Python module called CommandNotFound, and instead crashed. Well that’s a well-thought out tool.
Removing thousands of duplicate email messages from your email
Tags: Firefox, Gmail, Python, ThunderbirdI’ve been slowly loading all of my mail into GMail in an attempt to try to use the system as a better way to manage my email, “folder-free”.
GMail uses the notion of tagging emails with “labels” and “Archival” of messages instead of the classic mail folder heirarchy. Productivity experts higher-than-me continue to praise the system as being better, so I decided to give it a try… on 10 years of my email; over 300,000 messages.
But today I noticed that some of my larger mail folders had duplicate emails in them. LOTS of duplicate emails (one folder had over 15,000 duplicates!). Removing that many dupes from hundreds of local IMAP folders was not going to be a fun task…
I looked around to find some good tools to do it, and came up with several shell scripts, Python tools and other home-grown things, but nothing I wanted to really try on my large email archive.
Then I found the Remove Duplicate Messages add-on for the Mozilla Thunderbird Mail client. I don’t use Thunderbird, and prefer to use Evolution or Outlook 2007 for managing my PIM data now (yes, I really do use Outlook 2007, because frankly, nothing even comes close to functionality in the Linux space).
But I decided to give it a try. I configured my local IMAP account in Thunderbird, let it query my folder list and then installed the add-on. Here is the process to delete those duplicate messages:
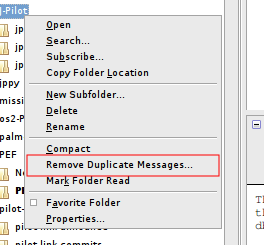
- When your IMAP account is configured in Thunderbird, expand the folder you wish to check for dupes.
- Right-click the folder and select “Remove Duplicate Messages” (highlighted in red in the screenshot below):
- A window will pop up after it scans for dupes, offering the following:
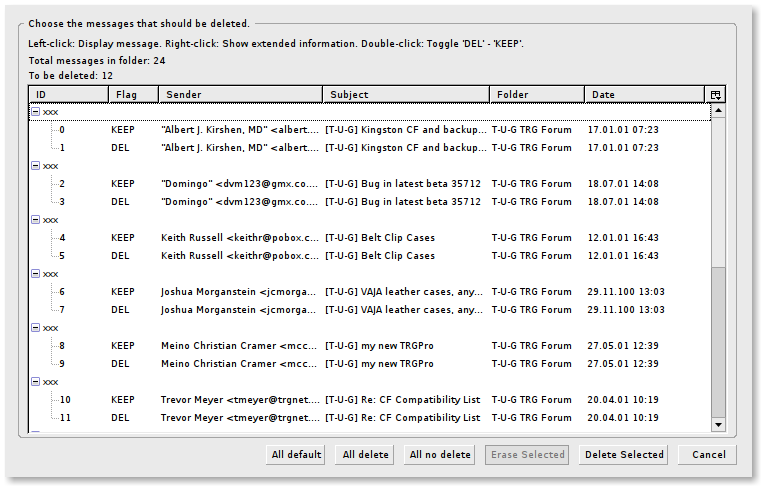
- Click on “Delete Selected” to remove the duplicate messages it found.
That’s it. It’ll move those messages to the Trash folder, and you can go in there later, right-click the Trash folder and select “Empty Trash” to permanently delete them.
Pretty simple and easy. Obviously make sure you back up your mail folders FIRST before you try any of this, just in case.
Update: After I ran this through all of my folders and deleted a lot of “legacy” mail folders (old 3Com palm-dev Palm mailing lists going back to 1999), I now have 144,962 messages in my local mail archive (a 52% reduction in number of messages).
Much better and easier to manage, search and back up to the FreeBSD backup array. It also removed 800M of space from ~/Maildir in the process.
Importing a decade of email into Google Gmail
Tags: Python, servers, syncI have over 10 years of email on my machine, which I refer to from time to time for various projects and historical reasons. Many of these emails are from very active mailing lists I’m still subscribed to. The total space consumed by all of these messages is currently 2.3 gigabytes, and it is stored in Maildir format.
I’ve been spending the last 2-3 years pushing myself to become more and more productive using a collection of various systems mostly based around David Allen’s GTD system. The whole premise behind David’s system is to “dump your head” into a trusted system, always filter every input through that system. There’s quite a lot more to it, but once you get the methodology down, it really, REALLY does improve how much you can do. Not only can you do more with less time, but you can do what you’re already doing now, and get a LOT more free time back in your day. No, seriously.
Click the image below for a full-size version:
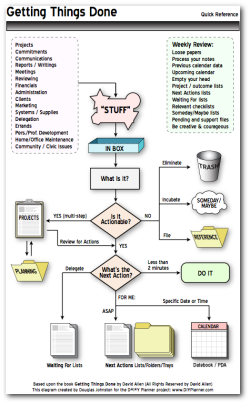
My own “hybrid†system encompasses analogue and digital formats, because of my specific and unique needs for the kind of work I do. At the core of the hybrid system is my PDA; a Treo 680 smartphone. If you want to see why I use a Treo instead of an iPhone, read my previous post on the matter.
Still with me so far?
Read the rest of this entry »
Just perl, nothing but perl, only perl.
Tags: PythonJust perl, nothing but perl, only perl.
-
I’ve been spending an enormous amount of time writing perl lately, learning a lot more than I thought I would on these projects, but it is definately fun.
Elegantly stripping Javascript and Style tags and blocks from a stream of HTML content in a scalar:
$html =~ s!<(s(?:cript|tyle))[^>]*>.*?</1>!!gis;
There’s so much I haven’t ever done with perl, using it only as a “sysadmin” tool in the past, but now I’m neck-deep in screen-scraping and all kinds of other uses for perl that I’ve never delved in before. Neat stuff.
Job Trends
-
No job yet, still looking for contract work to fill in the blanks.
The trend seems to be towards posting jobs with incredibly unrealistic job requirements for a pittance of a salary.
“Must have 10 years experience in HTML, XML, CSS, DOM, ASP, PeopleSoft, AutoCAD, Macromedia Flash, .NET, C, C++, Java, and be able to speak Spanish, Japanese, and write Sanskrit.”
“Oh, and by the way, we don’t offer any benefits.”
“Do you mind being our Senior Developer, leading up a team of 16 other developers, for $45k/USD a year?”
Yes, yes I do mind. That’s insulting.
It would seem that even if you send in a peper resume, make the calls, follow up, and get a real human on the telephone, one who is impressed with your skills and previous work experience, that it is all moot anyway. It’s like yelling at a tree in the forest.
The other thing I’ve heard (after sending in roughly 400 resumes and making about 70 phone calls myself), is that it doesn’t matter if you’re a perfect match for the job, with everything they require. If you’re not in the “first batch” of resumes they receive, you’ll never get a look.
A job posts an open position, and they get say.. 500 resumes in the first 2 days (a very low estimate, most are in the thousands by week’s end). The hiring manager will take the top 50 from the pile, and toss the rest into the trash (or “scan them in for later”, yeah, right). If your resume isn’t in the first 50 in that pile, you’re never going to get your resume seen or receive a call back.
I’ve sent out probably 400+ resumes in the last year (many of them were email-only contacts, no follow-up mailing address to send a paper copy of my cv to, or a business name to call around to speak to someone in charge of hiring), and made about 70 phone calls to places that were offering work. To date, I have only received one call from a recruiter, and it was from a word-of-mouth discussion at my local LUG meeting. The job was for something completely out of my skillset (Python and the “R” Statistical language). That’s a .002% return on my effort. My friends send me job postings all the time, which I follow-up on, only to find myself talking to a tree in the forest again.
Housing
-
We’re trying to find a house here in the area, so we can settle down a bit and stop paying rent. There’s so many nice houses, and a whole lot more houses that are complete trash, going for substantially more than their market value. Typically, the assesed value for taxes represents 75-80% of the actual market value of the house. We’re seeing houses listed for 90-100% over that value. A house assessed at $89k for example, will be listed for $225k on the market, in a not-so-nice area of the community. I just don’t get it. the interest rates are at 5.1%, and everyone jacks up the price of their house to compensate. It just ends up being a feeding frenzy.
We’ve got an agent now to try to help us find the “right” place for us. We go through about 2-dozen listings, drive by the places (without going inside), then take 4-5 out of those 2-dozen, and hand them to our agent to set up appointments to see the insides of. It saves everyone time and money to do it that way, so we’re not driving halfway across the state for a house we wouldn’t live in, just because the back yard borders an auto-graveyard for example (but of course, you don’t see that in the pictures of the houses online, noooOOOoo..). Tough work.
I’m ok with doing some renovations, but not moving plumbing and walls from one side of a house to the other. That’s a bit out of my league.
.oO(Now where did I put Norm’s phone number from “This Old House”)
Some random things about Advogato certification
Tags: linux, Perl, Python, syncBug Tracking
ishamael, the bug tracking package you seek is called Mantis. I use it quite extensively now on my server, and it works very well. I had to change some of the UI a bit and move some things around, but generally, it’s rock-solid. You can see it in action on one of my bug sites. Another you can look at is called RoundUp, and is really good. I tested 11 separate packages before narrowing down on these two. I chose Mantis in the end because it was PHP, and I didn’t want to have to burden my box with Python code, runtime, in the browser. You may also want to go here and see the other dozens of alternatives.
I can’t post much, in the middle of too much hardware hackery, but I’ve been reading all the diaries today and yesterday regarding the whole certification and trust metric issue and have to make some points.
deven
deven, you realize of course that by removing your certification of others when you were certified as Apprentice, that you have lowered their ranking, just as I removed your Apprentice status altogether by removing my certification of you. This is how the trust metric works, and it works well. Your point regarding the “Good ‘ol Boys Network” is completely unjustified, since you clearly don’t understand why Advogato exists. Nobody here is refusing people access to Advogato. Anybody can join. Anybody can post their diary entry. Anybody can contribute.
Your comment of:
“..Since most of Raph’s writings here seem to focus on effectiveness in keeping out the bad people, it’s not clear whether he ever paid close attention to the flip side of the coin, letting in the good people…”
If this were nothing other than a web-based forum without a hint of any certification metrics, created solely to discuss open source projects, like Blogger, would you have the same complaints? I would guess not.
To quote George Carlin:
“…a radio has at least two knobs; one changes the channel, and the other… turns it off!“
The value of certs here is not linear. If 10 people certify you as Apprentice, and they themselves are not even holding an Apprentice certification, you do not get an Apprentice certification. However, if raph or lilo or alan or myself certifies you as Apprentice, at the next sync, you will now be holding an Apprentice cert, even if nobody else certifies you. There is a very logical reason for that (and I wish it was applied to Slashdot and other projects as well).
You are measured here by your peers for your contributions to the free software community (and sometimes, non-free contributions, as some people here have talked about before). You are not “given” certifications. You earn them.
Again though, my desire to post my diary here has absolutely no bearing on the color that my name appears in. I didn’t start coming here because I wanted to gain some sort of status. I wanted to have a place to share my contributions, let people know what I’m doing (and if you read my diaries, they can be quite personal, ugly, and graphic at times, I have nothing to hide).
There’s a lot of cool things I do, as well as other people. I like to see what’s going on in the community I’ve been a part of for over a decade, and I like to watch it grow.
In your July 31, 2000 diary entry, you decided to certify yourself as Master, and I’m still trying to see what “important” free software project you are the author of, or what groups you mentor. Can you help me find it?
Your comments regarding the certification of God, Satan and Jesus are important, because they point out the lack of clarity in the people who are certifying these accounts. Look at rms for a perfect example. People don’t take the time to really understand the accounts before they go and waste certifications on them (hint: That’s not really Richard Stallman’s account).
As raph points out, there is a bit of weirdness going on in the certifications right now, and you have seen the trend also, but it fits exactly into the model which works here. The more people who join, the more uncertified users will exist, who are then going to be certifying already-certified users (sometimes wrongly, in the case of rms and others as above). This must be how you determined the system to be a “Good ‘ol Boys Network”, since the new users are the ones creating the dilution as you call it.
Here’s a tip: Ignore the certification altogether. Simply post your diary as you would have for any other site, and talk about what you’re doing in the community, free software space, open source space, or whatever. Relax. Have fun. If people respect you, and feel you’re doing “the right kinds of things” (subjective), then you may find yourself with a certification… or maybe not, but who cares. This is not gaining you PayPal bucks, or being used towards grading your GPA.
I respect the fact that you are doing development, and that you have taken the time to report some Mozilla bugs, but at the same time, you blather on about certifications. The two don’t jive. Free Software advocates and contributors give of themselves selflessly, often sacrificing deep into their personal lives to do it, and many times, unrecognized and uncompensated. Keep up the work, push hard, advance the status of free software where you can, and ignore what people think of you. There’s a famous quote I live by:
“There’s no defense for the truth”
If this isn’t working for you, there’s always Badvogato and Blogger.
{very}Hard{ware}
I am having nothing but trouble with my hardware here, and right when I need it the most, it fails me in exactly the ways I require of it to be working.
I have a single bootable RedHat cdrom I found in the back of a book here (Out of all of my linux cdroms, the only one I found to be bootable was in this RedHat Bible book, pft! No, bootable floppies were not possible, since I had no floppy drive, and even if I could install one in this machine, there was no way to get the images onto the disks, ugly all the way to the bank on this one).
After having to gut a production machine to get a the build onto the drive, it neglected to install perl (apparently Perl is not part of a ‘Development Workstation’ according to their installer, gar!). I decided to mount the cdrom in another drive, and map it over nfs.
But wait, my 3c905 Vortex NIC decides to start spouting packet errors and ghosted frames. I rummaged through my storage and spare parts and found one lone 3c509 ISA card, and put it into the box. Try again, no video. Wiggle some cards, move some slots, now I get video, but the cdrom in the other system fails on one lone file… guess which file I can’t read from the cdrom: perl_5.005.*.rpm. ARG! I can’t get a break!
dyork, you’re not off of the XML/XSLT hook with me yet… I have quite a handful of questions to toss your way. I’ll try to keep them en anglais for you.
Enough for me for today. I’m just not going anywhere near hardware right now. Maybe a good movie will get me distracted enough to concentrate on this when I get back tonight.
Lots of code and Canadian Cross Compilers
Tags: PythonWed Jun 20 02:28:55 PDT 2001
Spent all day working on cross-compiler toolchain building on SunOS and Intel architectures, including Canadian Cross builds with gcc-3.0, binutils-2.11, and gdb-5.0 for both ARM and m68k and m68k-palmos architectures.
Documented as much as as I could take (22 pages of material). The Embedded Linux Course is going well, but I just wish I had more time to work on it, and some more bandwidth to get to the material. Dialup at 14.4k with a 56k modem really hurts.
Spent the rest of the day fighting with Mantis bugs, and going the very-painful path of upgrading from 0.14.18 to CVS HEAD. Made about 1,000 fixes to the code for both “prettiness” and consistency
Then I hit a dead stop. Fatal bugs aplenty. I’ve posted 7 critical/fatal bugs today with it (0000591 through 0000597 over here. I really like Mantis. I really like where it’s going. I don’t like having to hand-reinstall these dozens of parts every time I upgrade though. It was a toss-up between Mantis and RoundUp. I leaned towards Mantis only because my server can no longer take any more hits from static Python binaries running under httpd.
The rest of the bug tracking packages out there failed miserably (I tested at least a dozen, from JitterBug to Bugzilla, GNATS, Double Choco Latte, Tracker, and a few others. rasmus has one he uses on bugs.php.net, which was nice, but not quite as full-featured as Mantis). These two are clearly the most powerful I’ve seen.
My end-goal of course, is to provide a nice, integrated, robust, set of tools for the developers that use my hardware and my free public cvs and to increase the speed with which we can close bugs and continue writing productive code.
I picked up two good books the other day. The first one is by John Douglas called Obsession, and is full of case studies of profiled killers, rapists, stalkers, and their victims. I’m about 1/2 way through this one, and it’s only 2 days old. The human psyche and forensic pathology along with investigative detective-type work are beginning to pique my interest.
The second book I picked up was by Steven King, called Insomnia, and is about an older gentleman who loses his wife, and slowly begins losing sleep a little each day. He begins having “visions”, which he thinks are hallucinations… I’m about 3 chapters into this one already. So far, it’s pretty good.
02:30 PDT, time for food and one more deliverable tonight before I crash.
<selfless plug>cert me</selfless plug>
SuperBoring 2001
Tags: Perl, PythonIts no secret, I hate the SuperBowl. It represents everything I hate about manipulation, money, and greed. It’s practically a national holiday now.
Presenting the instant replays in “Matrix-style” doesn’t mean that now they’re going to attract the analytical technology sector. I have better things to do with my time. For what they spend on 15 seconds of commercial time could buy me a nice house out here in the Bay Area.
I’m so glad I don’t own a television.
Perl and Python Experts Required, Apply Within
It’s that time again. Time to canvas the technology masses to help us work out the bugs in the Python parser for Plucker, and in the Perl version as well. The perl version as it stands now (though incomplete) is still about 700% faster in execution time than the Python counterpart, based on timings used purely on the gather-content portion of the code.
I don’t know enough about Python yet to help with that part, and some of the things in perl I’m trying to do are a bit outside of my current skill level.
Pain At 40,000 Feet
Another plane flight to the other coast. Let’s hope my ears and headaches can handle the altitude. I should be racking up these miles, but I never end up flying on the same airline. Ugh. I’ve got over 20,000 in the past year alone. Could I bring my snowboard and stay the weekend? Maybe my mountain-bike? I need to get out more.
Is she going to come out and see me?
So once again, my gut was right.
My friend Casey once told me:
“If you have all the facts, and it still doesn’t make sense, you’re being lied to…”